




























































Introduction
This film is an attempt to explore and understand how machine learning tools ‘think’ and ‘learn’ and how that impacts what they make. The story has been written intandem with generating the visuals so that the story creates the visuals and the visuals in turn influence the writing of the story.
The visuals in this film were created using a computational architecture comprising two parts: an ‘artist’ (VQGAN), generating thousands of images based on a series of words/phrases (yellow captions), and a ‘critic’ (CLIP) scoring and making selections from these images. Each panel simultaneously presents an alternative interpretation of the same words/phrases.
The artist and critic were trained using the Imagenet model which is made up of millions of images scraped from the internet that were manually annotated and categorised by human workers of Amazon’s Mechanical Turk marketplace earning an average wage of $2USD/hour.
These images are our images; interpreted and re-represented beyond our control or intention in an attempt to organise or map a world of objects. This is a political exercise with the consequence of perpetuating and amplifying cultural prejudices and biases that are enmeshed within the dataset. This system favours universalism over plurality and is already shaping a presentation of our world and transforming the future.
The audio narration was generated using text to speech synthesis of my voice.
You can participate and generate your own short films by tweeting a story or phrases to @ML_MOVIE. The generated film will be tweeted back to you.
Context & Research
The Theoretical Framework
It matters what matters we use to think other matters with; it matters what stories we tell to tell other stories with; it matters what knots knot knots, what thoughts think thoughts, what descriptions describe descriptions, what ties tie ties. It matters what stories make worlds, what worlds make stories.
— Donna Haraway, Staying with the Trouble: Making Kin in the Chthulucene
What matters is a matter of worlding. How we build knowledge, establish truths and imbue meaning is how we build worlds. It is an epistemological, ontological, ethical and political project. In 1988, Donna Haraway in her essay, Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective challenges the way Western culture presents knowledge. She described this as a presentation of disembodied, transcendent, universal truths and objective facts. This “view from above, from nowhere” she dubs the “god-trick”.[1] The trick is that behind the conquering, neutral gaze resides the “unmarked”, position of the male, white, heterosexual, human. The consequence of this is the rendering of all other positions invalid and held as subjective. A bias lens through which reality is described. A lens so vast that it can be hard to recognise and difficult to determine its edge.
Haraway argues for a materialist framework of “situated knowledges” that turns away from the objectivity-relativity binary. This feminist objectivity is about locating and positioning knowledge that privileges partiality as ‘the condition of being heard to make rational knowledge claims’.[2] All positionings are partial and open to critical re-examination - objectivity is accepted but all claims are not considered as matter of opinion so as not to fall into relativism.
In this framework, knowledge is contingent and based on embodied vision, that is, knowledge is limited to the location of the subject which is actively seeing and organising the world in an entangled relational ontology - the subject and object are not split - allowing for accountability for what we learn how to see. Haraway’s situated knowledges removes the guise from the “god-trick” and embodies it as just one, partial, way of seeing, making way for non-linearity, pluralism, and multivocality. It aims to bring multiplicitous, diverse experiences and orientations up to an equal level of that of the dominant one.
This project is a continuation of my interest in worlding and how structures of control within society influence cultural narratives and the way we construct knowledge. Haraway’s situated knowledges has been my guiding framework for critical examination of machine learning and datasets. For this work I am using text to image synthesis with VQGAN+CLIP - to examine how the machine learning architecture learns about the world from the training model. It’s a way to weed out an example of universal knowledge or “god trick” and prejudice rooted in technology and demonstrate the misconception of neutrality and objectiveness that we imbue technology with.
Imagenet & Taxonomy
Systems of taxonomy and classification such as the hierarchy of categories in datasets like Imagenet are political. They are foundational to how AI systems understand the world. The labels given to objects and concepts in images reifies them as such in the world through AI technology and tools. The hierarchy of classes and categories that structure the learning and knowledge of AI has the ability to perpetuate prejudice and bias inherent within those structures and inherited from the human creators of those structures. Simplifying things in the world to neat taxonomies eliminates complexity favours a universal definition or label for a thing in opposition to a plurality of meaning suspended by our unique relationality and knowledge of the objects and concepts of the world.
In 2009, the model was published as an alternative solution from having better algorithms for better decision making to having better datasets that reflect the real world to learn from for better decision making. Stanford computer scientist Fei-Fei Li claimed that their aim was to map out the entire world of objects.
ImageNet includes over 14 million images consisting of humans but mostly of objects. These images have been labelled and classified into 21,841 categories using Amazon’s crowdsourcing labor site, Mechanical Turk, and WordNet, a database of English words designed by the Princeton psychologist George A. Miller.
WordNet is like a dictionary where words are structured into hierarchical relationships rather than alphabetical order.
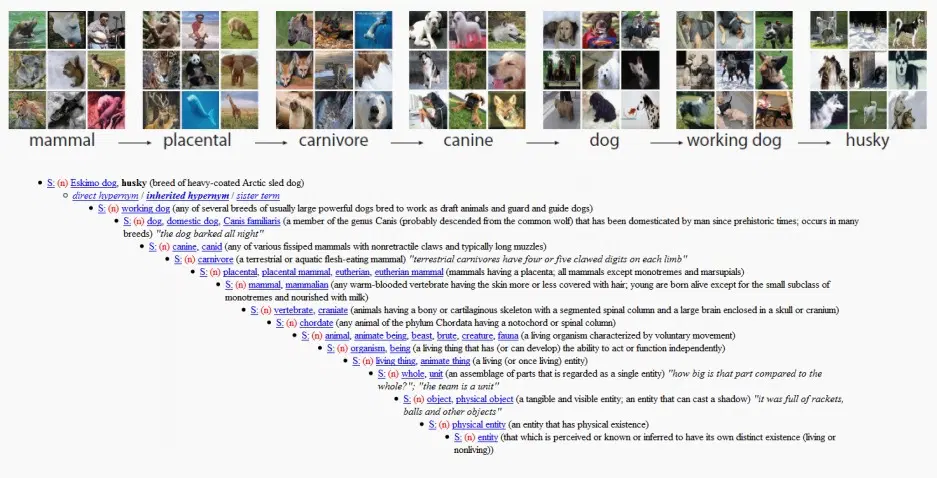
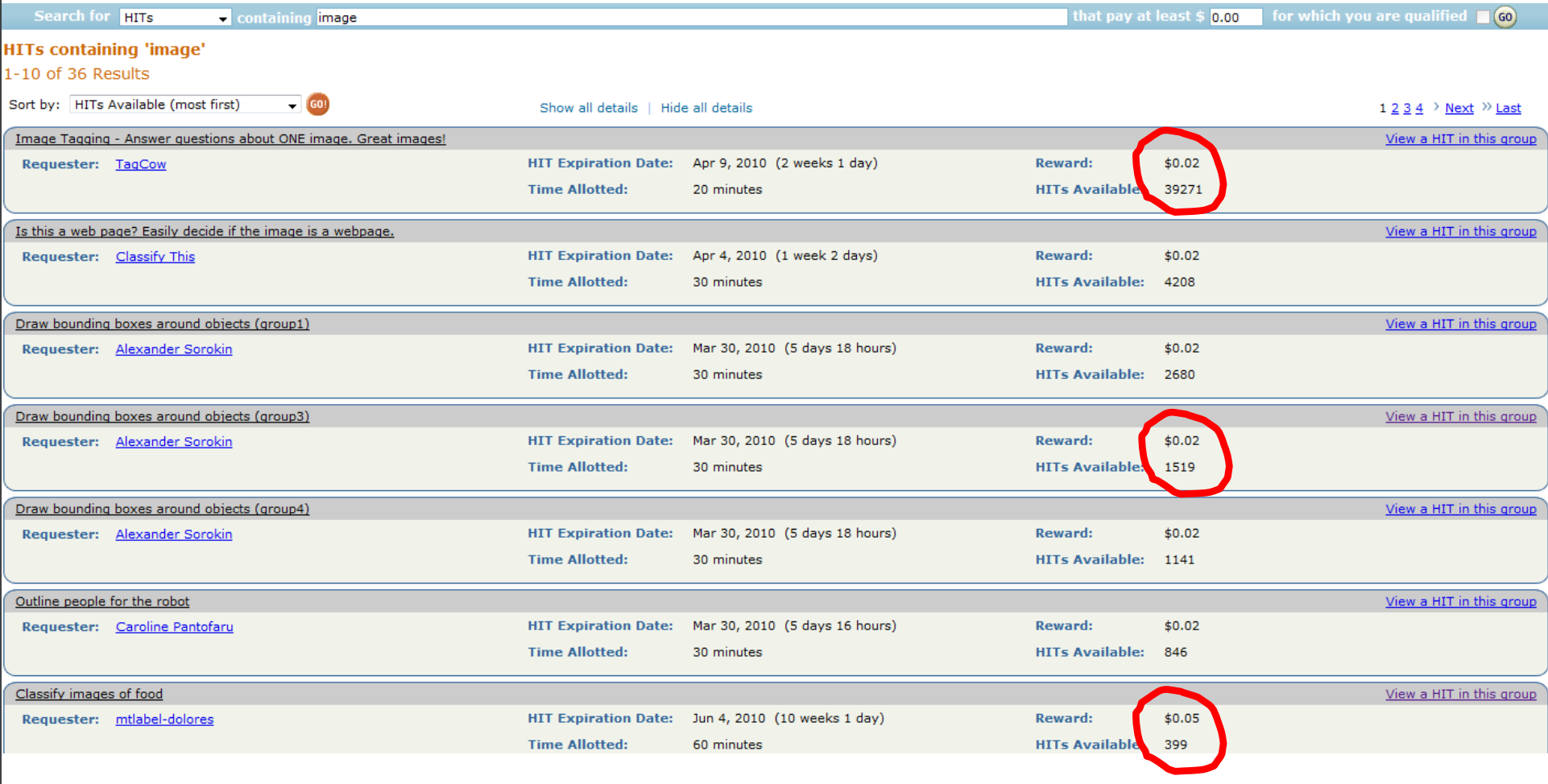
For the last 10 years or so it’s been used as a benchmark for the field of machine learning object recognition and has helped researchers develop algorithms they could not have produced without such a large dataset to work with.*
An image is worth a thousand words - whole disciplines of study are dedicated to interpreting and breaking down the meaning of images. They hold a multiplicity of meanings. It is quite uncontroversial to label an apple as an apple but when it comes to people the process becomes murky.
In ImageNet (inherited from WordNet), for example, the category “human body” falls under the branch Natural Object > Body > Human Body. Its subcategories include “male body”; “person”; “juvenile body”; “adult body”; and “female body.” The “adult body” category contains the subclasses “adult female body” and “adult male body.” We find an implicit assumption here: only “male” and “female” bodies are “natural.” There is an ImageNet category for the term “Hermaphrodite” that is bizarrely (and offensively) situated within the branch Person > Sensualist > Bisexual > alongside the categories “Pseudohermaphrodite” and “Switch Hitter.”
— Kate Crawnford & Trevor Paglan, Excavating AI.
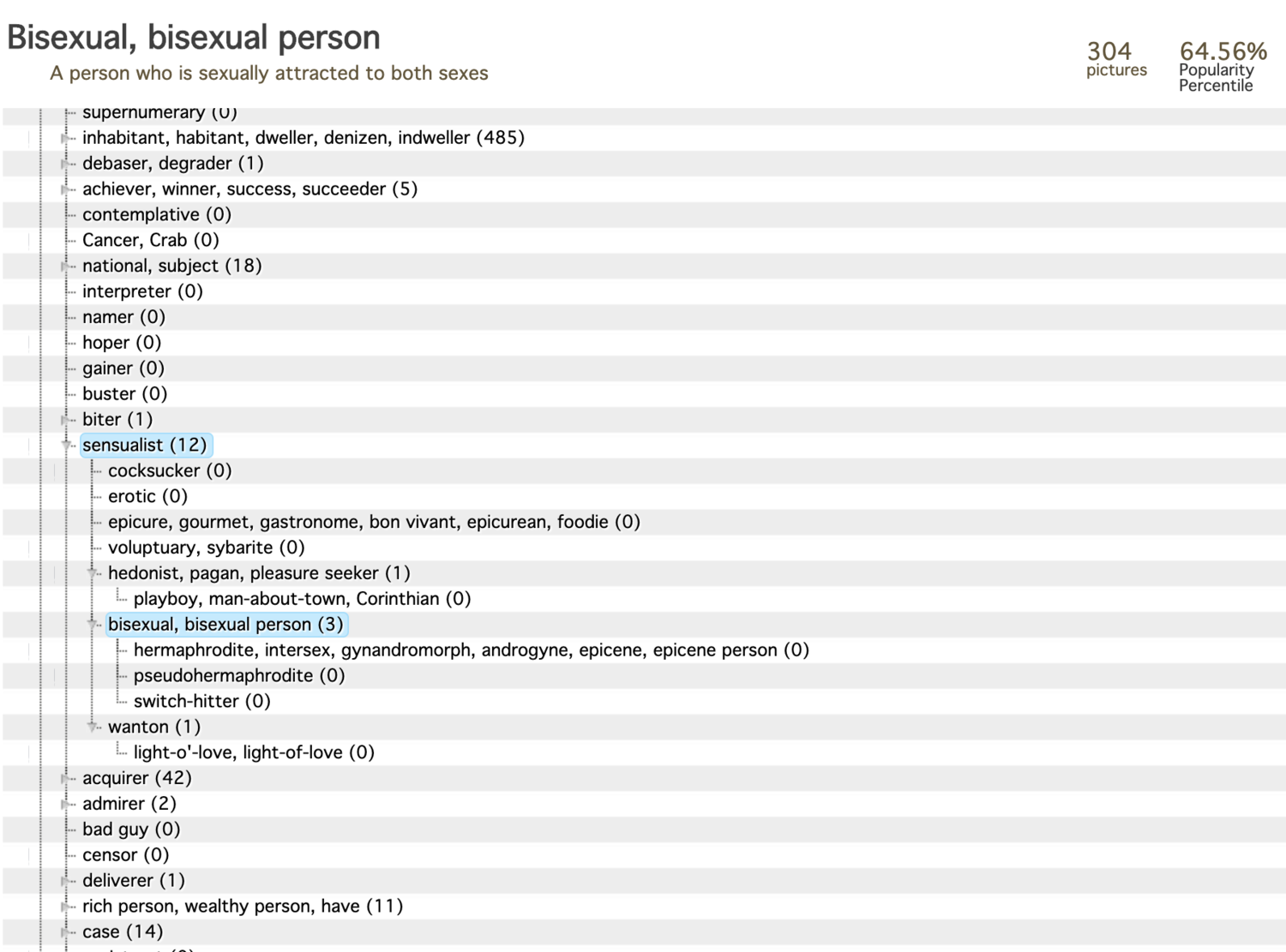
Other Person categories include, Bad Person, Call Girl, Drug Addict, Closet Queen, Convict, Crazy, Failure, Flop, Fucker, Hypocrite, Jezebel, Kleptomaniac, Loser, Melancholic, Nonperson, Pervert, Prima Donna, Schizophrenic, Second-Rater, Spinster, Streetwalker, Stud, Tosser, Unskilled Person, Wanton, Waverer, and Wimp.* Along with misogynistic labels and racist slurs.
In 2019, artificial intelligence researcher Kate Crawford and the artist Trevor Paglen created ImageNet Roulette, for their exhibition, Training Humans, at the Fondazione Prada in Milan.
You upload a selfie to the AI, which has been trained with the person data from ImageNet, and the image is identified and labeled with one of the 2,833 subcategories of people that exist within ImageNet’s taxonomy.
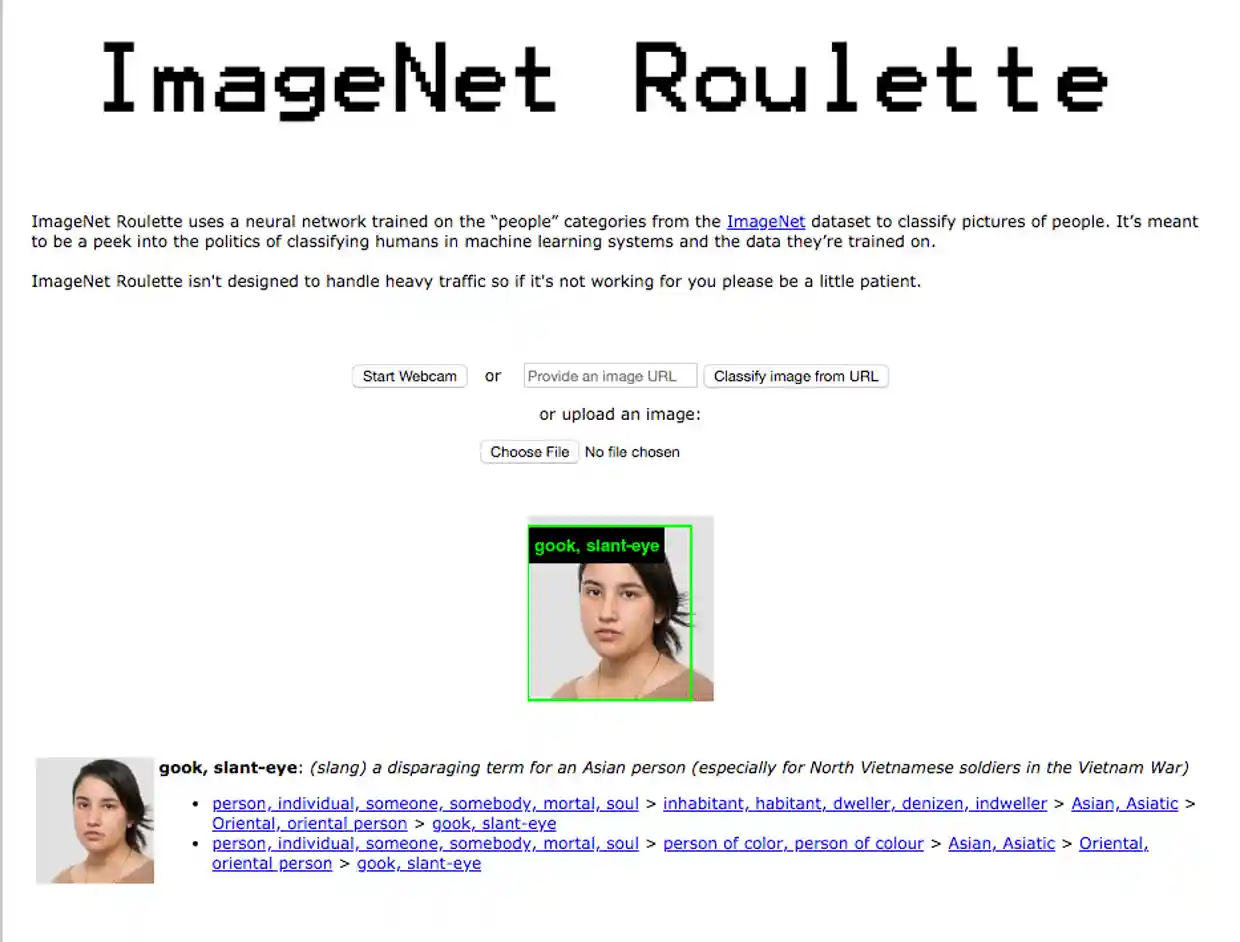
This project demonstrates how technology sees us as learnt from taxonomic structures created by humans. The machine has been trained to be misogynistic, racist and prejudiced. Humans have provided the technology with that quality. This dataset has been publicly available on the internet since 2009. It raises critical questions about the construction of datasets and the misconception that technology is neutral and objective. We must ask who is designing the structure of datasets, who takes on the role of judging the ontology and the definition of people and things, how is this information being verified, how can we create models that can run with cultural progress and changing of ideas.
Why metafiction?
Metafiction is a form of fiction with an awareness and emphasis of its own medium, construction and presence of the reader. I wanted to write the kind of narrative that responded to the process of storytelling intandem with generating visuals with machine learning and contained an awareness of what was being generated - a form of recursive story-telling in a cybernetic system.
I wanted to shy away from creative fiction and from demonstrating the kinds of psychedelic visuals the technology could generate and how it deals with abstraction. The aim was to examine how it understood the mundane everyday that it had learnt from the kinds of images people had posted on the web.
I used Donald Barthelme’s essay, Not Knowing, as an influence and launch pad into my story. I borrowed the first line from this essay, “Let us suppose someone is writing a story”. In his essay, Barthelme’s writes about conventional signs, bringing things into existence by announcing them within a piece of writing, deconstructing fiction and how it dissects it of its mysterious quality, the process of writing and not knowing what’s next, art making with computers and he traverses the planes of fiction and writing by referring to the characters, himself, bringing characters from his real world into the fictional dimension and blurring these boundaries. For the most part he claims that embracing the unknown should be position of writer and artist. (He claims, our advantage over technology in regards to making art is not knowing over the predictability over the machine - I do not necessarily agree with this in the context of this project and I will talk to this point later). The structure of this essay was not only relevant to the process of writing I wanted to pursue but also touched on the impacts of taxonomic structures in datasets - announcing things into existence has the same ring to it as how taxonomic classes and labels can perpetuate prejudice from the machine world via models created by humans back into the physical world as seen with Imagenet Roulette.
Embracing not knowing for artistic pursuit, as Barthelme writes about, was also my starting point for the making of this film. I did not know what the AI would generate and took it step by step and worked with the machine or against it. In this sense it's a collaborative project where I relinquished part of my control over the art making to the technology. It was partly but not wholly predictable. There is also the tension surrounding what the AI actually “knows”. I embraced not knowing what the AI would generate but also that the AI doesn’t exactly “know” what it’s producing either. It can understand the essence of things - it can generate an image of all the features of a face but they’re not exactly composed correctly. Hence the title Learning a blind eye. I’m working with a technology that has perception and understanding but does not exactly see the world as it is in the same way humans do.
Promptism
Promptism is a movement rooted in the technological advances of the 21st century that holds the potential to completely transform artistic practices.
Promptism was founded in response to the growing concern that traditional art had become irrelevant to the modern world. Going beyond painting and sculpture, Promptist art involves the manipulation of new media, specifically computer generated imagery, animation, and the Internet. Its unique dynamism makes Promptism a dynamic vehicle for the expression of identity and the implementation of real-time feedback between itself and the spectator.
— The Promptism Manifesto, 2021
The Promptism Manifesto is an AI Art manifesto written for AI art by a GPT-3 model.
This project falls under the umbrella of promptism art. This new technology destroys the traditional art concept of artists-as-individual. It uses open source technology (VQGAN+CLIP) that has been developed and improved in many stages by multiple people. The model used for training involves the labour of many individuals - those that have furnished the internet with their images since that capability existed and the many mechanical turks that have helped to class and caption the images. Google Colab provides a free platform that brings powerful GPUs into the home of anyone with a sturdy wifi connection. This accessibility and discords, reddit forums and Twitter have allowed people to connect and share their art generated with their prompts. The artist no longer has to be an expert in code or skilled in wielding a brush nor does visual work need to be created by the artist. The uniqueness of the art comes from the prompts. In my case, the visuals are created with VQGAN and CLIP with the Imagenet model. I have created the prompts, the story and pieced it all together.
For further reach beyond the exhibition space and to build on the idea of open source, plurality of knowledge, collaborative art making and accessibility I created a notebook that uses the Twitter API to automatically collect short stories tweeted at the account I created for this project, use the stories as prompts then tweet them back to the people that posted the story.
Technical
Text To Image Synthesis - VQGAN + CLIP trained with ImageNet in Google Colab
I ran this project through Google Colab. Google Colab, allows you to write and execute Python in your browser and gain free access to GPUs. No configuration is required. Google Colab Notebooks timeout after 90 minutes or 12 hours with the pro version which means every new run of the project involves installing and importing files and libraries that are required for the project. Only the executable cells remain. You cannot host continuously running apps on Google Colab but there are ways around this.
In the previous semester I created a project generating still images with machine learning by prompting the AI with text. That machine learning architecture was BigSleep - a combination of neural networks BigGAN and CLIP. This was created by Adverb (@advadnoun/Ryan Murdock). I began testing with BigSleep - trying to make a film by using the images from the run as frames that could generate a video. These early tests were quite abstract and clunky and not producing the realistic images machine learning was capable of.
BigGAN+CLIP test with prompt 'struggles against universalism'.
I contacted the developer/artist that had written the BigSleep Google Colab that I had used and built upon. He responded by telling me that architecture was now dated and the new architecture replaced BigGan with VQGAN. This had been introduced around April 2021 by Katherine Crowson (@RiversHaveWings).

BigSleep:
Adverb described the process as:
BigSleep searches through BigGAN’s outputs for images that maximise CLIP’s scoring. It then slowly tweaks the noise input in BigGAN’s generator until CLIP says that the images that are produced match the description. Generating an image to match a prompt takes about three minutes in total.
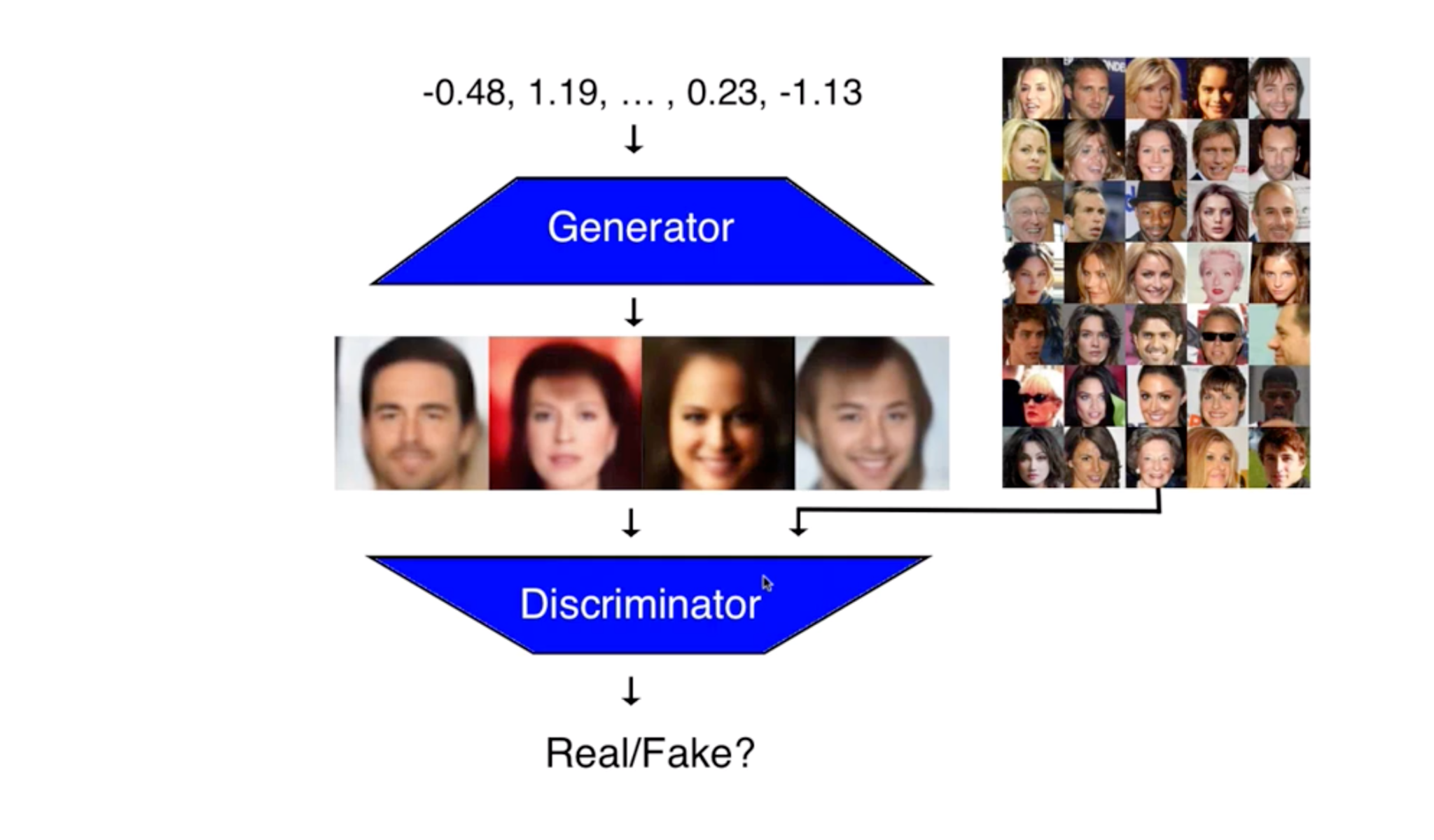
BigGAN:
BigGAN, is a system created by Google that takes in random noise and the generator then transforms this noise into a meaningful output - images. It's a single model trained on 1,000 categories from imagenet which allows it to synthesis different kinds if images. BigGAN is a generative adversarial network: A pair of duelling neural networks - an image-generating network and a discriminator network. These are trained simultaneously. Over time, the interaction between generator and discriminator results in improvements being made to both neural networks.
CLIP:
CLIP, is a neural net made by OpenAI that has been taught to match images and descriptions. Give CLIP text and images, and it will attempt to figure out how well they match and give them a score accordingly. Meaning, CLIP is a neural network for steering image creation to match a text description.
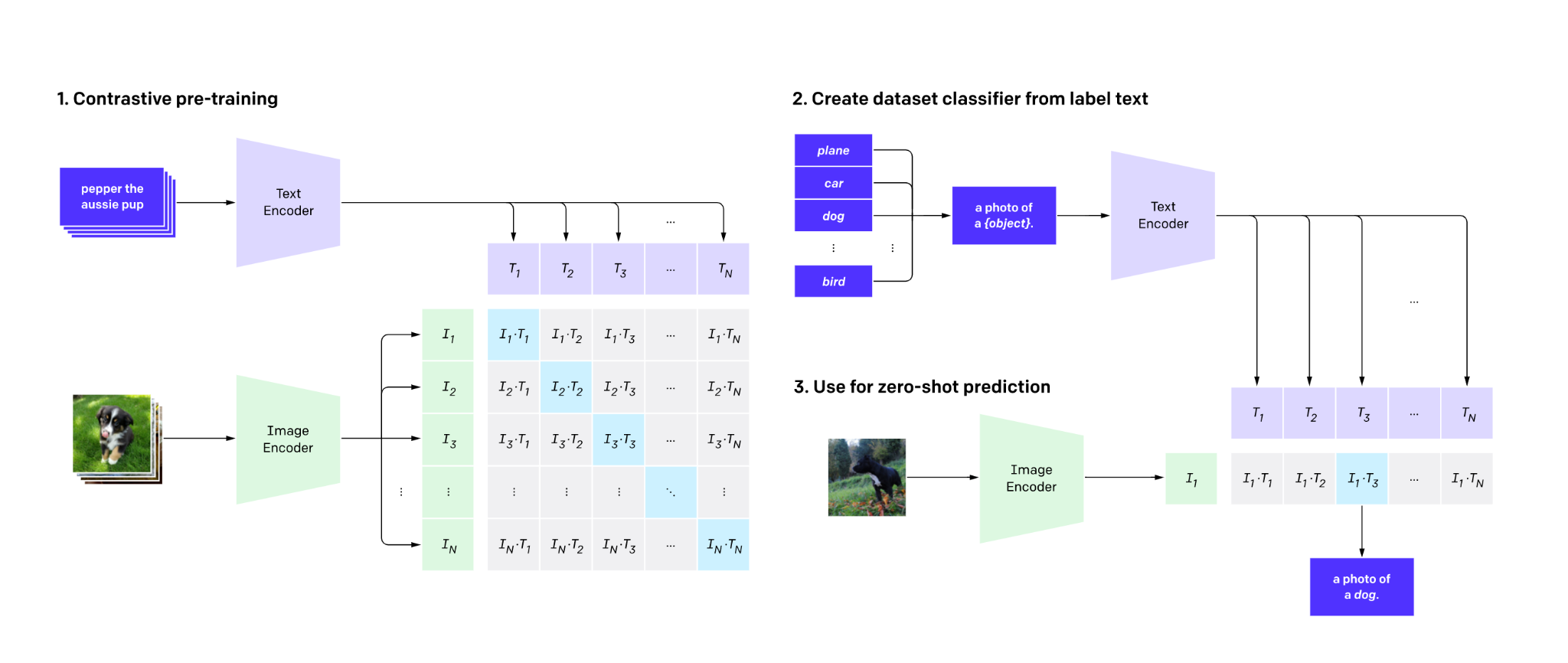
To do this, CLIP uses an image encoder and a text encoder to predict which images are paired with a given text in a dataset. That behaviour is then used to train a zero-shot classifier that can be adapted to several image classification tasks.⁵
Encoder:
Encoders take the images or text or whatever data it is trained on and then compress it into a feature vector which holds the information that represents it.⁶
Zero-shot classifier:
Zero shot learning is the approach when the neural network is forced to make classification for classes it was never trained for and needs to predict the class they belong to. For example, given a set of images of animals to be classified, along with textual descriptions of what animals look like, an AI which has been trained to recognise horses, but has never seen a zebra, can still recognise a zebra if it also knows that zebras look like striped horses.
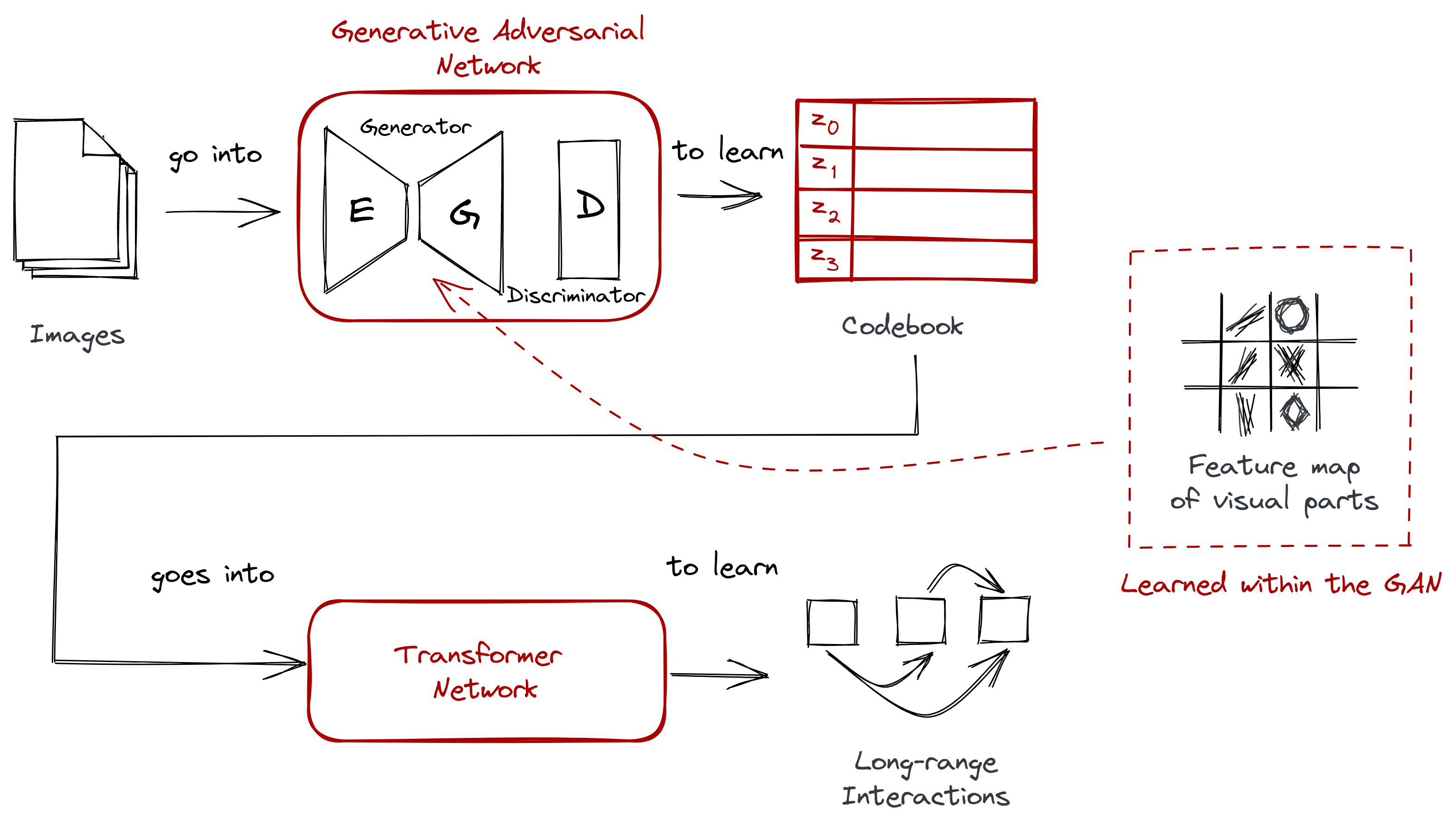
VQGAN:
VQGAN stands for Vector Quantized Generative Adversarial Network.
The way they CLIP and VQGAN work is that VQGAN generates the images, while CLIP scores how well an image matches the text prompt. The goal is a good score. CLIP is guiding VQGAN by searching through VQGANs latent space to gain a good score/accurate image.
Most computer vision techniques think in terms of pixels like convolutional neural networks (CNN). This allows us to “compose” pixels together and learn visual parts. VQGan does both of these things - learn the visual parts of the image from its individual pixels but also understand the relationship between these parts.
Vector quantization (VQ) is a signal processing technique for encoding vectors. What this means is it understands a group of pixels that could make up, for example, an eye. This eye or vector can then be represented as a single centroid (codeword) making it less computationally expensive. The pixels of an image become a dictionary of centroids (codebook) and their corresponding members. This codebook goes through a transformer. Transformers are used in natural-language processing, and model long-range dependencies between symbols - words, phrases, and sentences - which allow for a way of training for perception and relationships between things. Essentially, what this means is we can have a codebook of ‘chair’ and ‘person’ and through the method of training with transformers the relationship and perception of a person sitting on a chair can be taught to the AI.
The Process - Creating the Video
The Google Colab notebook I used for generating images written by Katherine Crowson. The keyframing features of zooming and rotation was added to the notebook by Chigozie Nri. I edited bits of the code to suit my needs but mostly I added trouble shooting fixes and experiemnted with the parameters to produce the video with necessary effects. I used ImageNet to train the GAN because I was interested in what a model trained with 14 million images from the internet would produce - what would it tell me about the images people post on the internet?
I would run a text prompt through the parameter along with the amount of zoom and rotation angle I wanted over the course of the run. I ran each prompt for 150 images for the export of a video using 12 frames per second.
Each image is treated as a key from during the run so through each iteration the zoom and rotation will change incrementally according to what’s been set for that point throughout the sequence of all the key frames. For example:
TEXT: 150:( someone is writing a story: 1 | writing: 1 | photorealistic:1 )
The 1 here constitutes the value of the prompt. 1 is 100% of that concept. You can use 0 to try and remove things from being generated - exclusionary prompts.
ANGLE: 1: (1), 37.5: (1.05), 75: (1.1), 112.5: (1.015),150: (1.2)
At key frame 1 degree so the image is not rotated but by the time the run reaches the 150th image the image would rotated to 0.1 of a degree and the images between 1-150 will have moved incrementally in order to reach 0.1 byt the 150th.
ZOOM: 1: (1), 37.5: (1.005), 75: (1.01), 112.5: (1.015), 150: (1.02)
The zoom works the same as the angle calculation. I set the key frame number and the amount of zoom I wanted at that point in time.
I could have set the zoom and angle at the first and last frame but it did not produce steady linear results which is why I divided the frames up into quarter time and set an even pace of values for smooth linear results.
After each run I would use the last frame, or image, generated and use it as the starting point for the next run with a new prompt to allow for a smooth transition between videos when they were spliced together later in Adobe Premiere Pro. I generated over 3000 images for the triptych.
The story was not pre-planned. It was a process of prompting the AI (yellow captions in the video) then waiting for the visualisation of the prompt then responding to the visuals with another prompt along with writing about what was being generated (white captions in the video) in keeping with the style of metafiction.
In some cases I chose to write prompts with the hope of generating something that would make sense as the next scene or sequence to a visual story. For example, “two people on a journey” generated what resembles the interiors of trains and buses so the next prompt included what might be seen outside the windows during a train or bus journey. Other times I would attempt to reiterate what was being generated previously, “disembodied ears, eyes, mouths, teeth”, other times I would fight the machines propensity to over generate teeth, eyes and other human features by listing inanimate objects along with adding exclusionary prompts (people=0) so people would not be generated. It was a collaborative effort where my control over what was generated was limited. At times the AI would continue to generate objects that would not relate to the prompts and inevitably resist my efforts of exclusionary prompting and continue to generate parts of human features and flesh. It’s almost as if its obsessed with the bodies and faces and wants to keep creating them. Another obsession was logos. When I was trying to generate something that resembled black murky waters for the introduction teeth would begin to appear along with a plastic water bottle:

During testing I found that many of the images generated had a pornographic nature despite not having any prompts relating to humans or animals which made me very curious about the associations with the prompts I used the captions of the images that were used to train the model:

What I found really interesting about the machine generation was learning how it saw the world based on the model, how it understood what made up, say a person, but couldn’t quite put all the features together in the correct place, how the three films generated very similar results even though they followed their own path by using the last image of the previous run. The machine has a very consistent understanding or view of the world from the model and the things in it. Also, as hard as I tried by using exclusionary prompts and non-human prompts, the machine would always lean towards generating human features.
What I found unsurprising and unfortunate during the generation of my story was that the “people” were always white. This could mean two things - there are more images of white people than people of colour among the 14 million images and the images of white people are captioned and classed in the taxonomic structure as simple people but people of colour are specified to be so rather than just referred to as ‘people’. Meaning white is the default and the norm according to the training model and the AI.
The Process: Twitter Integration
The twitter videos did not include the keyframing functionality to make the process lighter. To integrate this project with Twitter and invite a wider audience I added the necessary code library (Tweepy) that would communicate with the Twitter API to fetch statuses that had been tweeted to my Twitter account @ML_MOVIE, save the IDs to a json file on my Google Drive to track and update which tweets have already been generated, then split the new Tweets at ‘.’ and ‘,’ and use these the split phrases as prompts to generate.
For example, with the tweet: @jo____gr I am walking with my brother on a field of one thousand images. We understand each other, the sun is shining, it’s a beautiful day.
The Tweet is fetched and split:
- I am walking with my brother on a field of one thousand images.
- We understand each other,
- the sun is shining,
- it’s a beautiful day.
Each phrase is used to generate 500 images. The 500 images from each run are then exported as frames of a video and the video is tweeted back to the tweeter:
@jo____gr I am walking with my brother on a field of one thousand images. We understand each other, the sun is shining, it’s a beautiful day. pic.twitter.com/FQ0FhRyZNH
— Machine Learning Movie (@ML_MOVIE) September 11, 2021
@Rickleton at the queer football game I got stung by a wasp. pic.twitter.com/6vKACjAl6f
— Machine Learning Movie (@ML_MOVIE) September 11, 2021
@marisaofworld the black camel walked along the desert. The sun filled the sky. pic.twitter.com/lbPnnn8xF6
— Machine Learning Movie (@ML_MOVIE) July 29, 2021
As previously mentioned Google colab cannot run as a continuous application so my plan was to run the code at the end of the exhibiting days to collect, generate and post the new tweets. Unfortunately, only a few friends tweeted to the account after my request. The instructions were on a small sign and not noticed. I should have placed them at the end of the video so people would have noticed the instructions.
Voice Synthesis - Tacotron 2 + Waveglow, Resemble AI
The Tacotron 2 and WaveGlow models form a text-to-speech system that enables users to synthesise natural sounding speech from raw transcripts without any additional information such as patterns and/or rhythms of speech.
Tacotron2 generates spectograms from text and Waveglow generates audio from spectograms.
I used two Google Colab Notebooks for this process:
1. to fine-tune a pre-trained model with my voice using this Machine learning technology
2. to then synthesis the the text to speech with my model.
These notebooks were created by CookiePPP. They are part of an open source My Little Pony Preservation Project - a project where fans of My Little Pony have been working together to clean the audio from the episodes of the series to then train a model with the characters’ voices and synthesis them.
I recorded my voice reading sentences within 10 seconds in length. The wav files and corresponding lines of text are both used to fine-tune the model. I recorded an hour of audio and was able to reach a point where my model was able to say numbers clearly ( the “3, 2 , 1” in the film) and a few words such as “personhood”. The model had my tone and timbre but sounded like the kinds of sounds I would make in my sleep - mumbling gibberish:
I was not going to be able to reach the point of having a fully trained model by the exhibition so I used the online app, Resemble.AI (https://www.resemble.ai/), to create an AI version of my voice for the narration of the story.
I used the model I trained for the countdown in the video and as the background noise. I generated the audio from my model using the same narrative text used for the Resemble model. I added audio effects such as auto tune, pitch shifting and played with the equaliser to give it clarity. The result was a more harmonic effect instead of constant sleepy mumbles. Without the effects it was too similar to the narrative voice - as they were both trained with my voice and sounded like me - which distracted from the narration.
Install + Projection Mapping - Touch Designer
I requested a bay window area in order to hang my triptych film angled towards the viewers in the centre. After being assigned to a very tall space with shallow depth, I wanted to project from the top of the window frame to the floor and install a reflective surface on the floor to create an immersive experience surrounded by the projection. The projector I was assigned for this task, however, was not available and instead the projection was at a lower resolution and didn’t reach the floor but was still very tall. The windows were deep and had many ridges which would have obscured the detail in my film so I used rubber projection screens that hung from around the top of the window to the floor at about five metres.
I wanted to eliminate the room for error during the exhibition so rather than choosing to run openFrameworks with the PiMapper add-on I researched different projection mapping options that would allow me to projection map and then export a movie file that could play on a loop using a media player or laptop throughout the exhibition. This allowed for very little to go wrong and very little operational instructions for invigilation. TouchDesigner was a new program for me but the quickest, cheapest and easiest solution.
There were going to be many sound works in the exhibition and rather than negotiate with other exhibitors about how the audio could effect their works I simply opted for headphones to play the audio narrative. Three headphones which sat upon three simple stools connected to a headphone amp in the front left corner of the room with an audio cable that ran to the laptop at the back of the room which was connected to the projector with a HDMI cable. The projector was cable tied to a shelf three meters up the back wall.
The church bay window panels in place of the stained glass windows of the space was an intimation to our worshiping of technology and the misconception of its inherent truth and objectiveness - taking it as gospel. I chose the form a a triptych to display the work to play on the idea of universalism and plurality - the story was generated three times but each film is very similarly because the training model has taught the AI to have a simplified understanding of the world rather than a complex one that is able to interpret the relational ontology of a world of people.




Self evaluation
This was my first exhibition install and I definitely learnt that communication and getting things confirmed from the beginning is key. Many things can go wrong in regards to an exhibition install and I know for next time to have back up plans. The project would have worked better in a darker space - perhaps a room painted black - and with a higher resolution projector. The edges of the projection were slightly jagged from the size of the pixels and the lines not being perfectly straight to fit the lines of the screens in the space.
As I mentioned earlier I did not display the instructions to interact with Twitter well. This was really unfortunate and meant the project missed another level of engagement. This was an important lesson but I have not given up completely on this part of the project - I will continue to share the opportunity fo people to interact with this project over social media accounts so the project can continue beyond the exhibition period.
I didn't write the machine learning architecture code which when undertaking a Computational Arts course is something I feel like I should be doing. I did have to research and understand how the technology works and learn Python for trouble shooting which was a large learning curve. I could have made something more interactive, for example, I could have had people generate their own stories in the space. I researched this and it was beyond my financial means as I needed to have powerful GPUs to run locally to power the app or spend an inordinate amount of money on hosting services like DigitalOcean. It was not beyond my technical means as I had previously coded a python text generator app with machine learning which is hosted on DigitalOcean.
I could have constructed my own model with my own images and captions but I wasn't looking to understand myself better or how a machine would perceive me. I wanted to look beyond myself and focus on structures of meaning and knowledge transferred from people to machine and back again in general. I wanted to use the ImageNet model because it's an enormous amount of data and I wanted to learn about what people post on the internet - what's worth taking images of and sharing online. ImageNet calls for very political examinations due to its problematic construction and taxonomic structure. This video does not make pointed accusations and criticisms of the model, not because I do not wish to make a strong political piece but because this is the beginning of my research into this area and I want more time to treat these issues with the focus and project they deserve. This project has touched the surface, introduced key issues, and in time I will go deeper and further develop this project and the explore the political, ontological and ethical issues surrounding machine learning technology.
My educational background is in philosophy and literature and I wanted to bring my computational work into my practice which focuses around how knowledge is constructed and meaning making and explore new ways of story-telling and exploring narrative with technology.
VQGAN is very new and what has been produced thus far has been very abstract images and videos shared across Twitter. Holly Herndon has also collaborated with developers to create short videos and Nemo Atkins has recently posted an example of this technology to his instagram. My work differs from Atkins and Herndon in that I've written a story without a plan in mind but rather in collaboration with the technology. Herndon has created scenes with little change and Atkins has created video with sequences which he has planned from the beginning. He has used prompts with changing values throughout the keyframes in the way that I have with angles and zoom. I have created something unique for this technology while it's in its infancy although things move quickly and I'm most likely not the only one to have used the technology in this way.
References
1 Haraway, Donna. “Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective.” Feminist Studies, vol. 14, no. 3, 1988, p. 589. JSTOR, www.jstor.org/stable/3178066. Accessed 10 May 2021.
2 Haraway [1] p.589.
Crawford, K & Paglan, T. "Excavating AI". , 2019, https://excavating.ai/.
Barthelme, D. “Not Knowing.” Not Knowing: The Essays and Interviews of Donald Barthelme. Ed. Kim Herzinger. New York: Random House, 1997.
Gershgorn, Dave. "The Data That Transformed AI Research—And Possibly The World". Quartz, 2021, https://qz.com/1034972/the-data-that-changed-the-direction-of-ai-research-and-possibly-the-world/.
Johannezz. "The Promptist Manifesto". Deeplearn.Art, 2021, https://deeplearn.art/the-promptist-manifesto/.
Lee, Fei-Fei. "Crowdsourcing, benchmarking & other cool things" ImageNet, 2010, https://image-net.org/static_files/papers/ImageNet_2010.pdf.
Lee, Fei-Fei. "Where Did Imagenet Come From?". Unthinking.Photography, 2021, https://unthinking.photography/articles/where-did-imagenet-come-from.
Markoff, J. "Seeking A Better Way To Find Web Images (Published 2012)". Nytimes.Com, 2021, https://www.nytimes.com/2012/11/20/science/for-web-images-creating-new-technology-to-seek-and-find.html.
Miranda, LJ. "The Illustrated VQGAN". Lj Miranda, 2021, https://ljvmiranda921.github.io/notebook/2021/08/08/clip-vqgan/.
Rogowska-Stangret, Monika. “Situated Knowledges.” New Materialism, newmaterialism.eu/almanac/s/situated- knowledges.html.
Shen, Jonathan et al. "Natural TTS Synthesis By Conditioning Wavenet On Mel Spectrogram Predictions". Arxiv.Org, 2021, https://arxiv.org/abs/1712.05884.
Wong, J C. "The Viral Selfie App Imagenet Roulette Seemed Fun – Until It Called Me A Racist Slur". The Guardian, 2019, https://www.theguardian.com/technology/2019/sep/17/imagenet-roulette-asian-racist-slur-selfie
"Introduction To VQGAN+CLIP ". Sourceful.Us, 2021, https://sourceful.us/doc/935/introduction-to-vqganclip.