




























































"Human?": Networked Creativity
"Human?" is an interactive installation where the viewer can draw a face under a webcam, whose input is passed to a conditional generative adversarial network that has been trained on photographs of human faces. The displayed result is what the trained model "predicts" is in the image - since it has only "seen" photographs of faces, it applies a kind of pseudo-photographic texture to contours that resembles faces. My initial incentive was to discover our assumptions about what it is to be human through a pictorial conversation with a machine that attempts to emulate the human mind, but what I found was not so much the likenesses and differences between the human and the machine, but the larger techno-cultural assemblage that produces art with a sort of a networked creativity. This report is about this new creativity, and the whereabouts of creative ownership therein.
produced by: Keita Ikeda
Introduction
My goal for this report is not to narrow down what creativity might mean in the field of computational arts, but to expand it. My argument is that in generative art, especially in works that engage with the technology of generative adversarial networks as a medium, the work belongs not only to the artist, but also to the techno-cultural network that produced it (if the notion of creative ownership is relevant at all). The author has been long dead in the fine arts and the beauty is in the eye of the beholder, and in this case, the beauty might be in the network(abrthes, 1967). I will first outline what creativity might mean, and its relation to perception and embodiment. I will then delineate the situated specificities in which this project was undertaken, and discuss how the construct of the individual author may not be applicable to it; rather, the work is an emergent product of the techno-cultural assemblage. To support my argument, I draw on the framework of phenomenology and take a relational, non-anthropocentric approach in my analysis.
Creativity, Perception and Embodiment
So what is creativity? In their essay "Addressing the “Why?” in Computational Creativity: A Non-Anthropocentric, Minimal Model of Intentional Creative Agency", Guckelsberger et al. state:
"there is general agreement that creativity does not occur in a vacuum: it is a situated activity, in that it relates to a cultural, social and personal context. However, it is also physically conditioned on an agent’s embodiment and structured by how an agent’s morphology, sensors and actuators shape its interaction with the world." (Guckelsberger et al., 2017)
They recognise the contextual and embodied nature of creativity. This is not a surprise, since creativity seems to have an inextricable relation with perceiving. As Michaelangelo put it, "Every block of stone has a statue inside it and it is the task of the sculptor to discover it" - the sculptor must see a form inside the block of stone through what they already know about the world, using their abstracted knowledge of what something is. One might see a cat when looking at a block of stone with a round form and two extrusions on top, for example. This is, in fact, how an generative adversarial network works. Once it has been trained to classify images of cats, the process can be reversed through a technique called backwards propagation to produce images of cats. "Seeing", or having a generalised understanding, enables creating.
Let's look at Perception through a more theoretical lens. In his seminal work Phenomenology of Perception, Maurice Merleau-Ponty argues that embodiment is key for perception. He rejected the Cartesian dualism of body vs mind, and made a distinction between sensation and perception; sensation is the raw input, if you like, and perception is the way in which we make sense of the world, based on what we know about the world through bodily experiences (Merleau-Ponty, 2002).
So, then, if computers, with webcams as their eyes and GPU as brains, can take in, process and output information, can they not said to have an embodied existence? And that they can be creative? (spoiler: probably not, at least not yet, and not on their own)
Artificial Intelligence and robotics researcher Rodney Brooks proposes that cognition is an emergent property of action, and does not precede it (Brooks and Steels, 1995). He is generally critical of the level of success of artificial intelligence as cognitive beings, and I agree with him. Cognition is a phenomenon that arose from the incredible complexity of nature, and AIs, including my little system, is nowhere near close to that of, say, a human child. If Cognition is an emergent property of action as Brooks suggests, then calling an artificial neural net a cognitive being would simply be false; action entails intention, and neural nets have no intentionality. They have no desire upon which to act.
There is intention in this project, however, in that I conceived it with the creative goal to explore the likenesses and differences between machine and human ways of seeing. As such, the creative ownership of the piece seems to belong to me, and me alone - But hear me out.


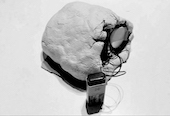
Above: output when the model sees no faces. Drawing by Luke Dash.
Networked Creativity
So far, we have talked about creativity as belonging to an "agent" per Guckelsberger et al and Brooks. I however feel that, given the vast number of elements involved in GAN art, we can no longer talk about its creative ownership as belonging to any one of the elements in isolation, and the preoccupation with the human vs machine dichotomy and "humanness" is perhaps not so useful here. I trained the model with the intension that some output be generated - but I had no idea what the outcome would be until I ran the program. I honestly cannot say that I feel like the creator of the images that the program has produced. I used non-funnelled (not cropped to the faces) images, taken from news websites, because I wondered what the generalised backgrounds would look like when there was such a wide variety to them. The result was a backdrop of wave of vibrant colours, an aesthetically pleasing outcome that I could not have predicted (see image above).
The dataset also brought with them the sociopolitical environment in which it was compiled. The skin tone that the programs draws is always pale, because the individuals in these images are predominantly Caucasian. The algorithm is also not my own - it was written by Isola et al., and the implementation is by Christopher Hesse. And as we can see, no data or algorithm is free from its context - they all materialise as "coded gazes" (Amaro, 2019). I cannot say I have complete creative ownership over this work, for better or for worse.
All art is situated in the context in which it was produced, and no artist is the sole creator of any given work. But computational art, especially works that rely heavily on data and borrowed code such as this one, complicates the question of creative ownership even further. To generate a more appropriate understanding, we must look at the network that produces these works, in which each element is actively engaged with, to the extent that it cannot be reduced to being merely part of the "context".
As I started outlining above, there are many elements to "Human?" (and any other work that utilises GAN). Firstly, the data that is used to train the model, which inevitably has sociopolitical biases; Second, the algorithm and its implementation. It is often the case that, especially higher-level libraries, its inner workings are a black box with human biases implicitly encoded into it; Third, the hardware. These powerful neural nets would not be possible without the recent advancements in hardware, specifically graphics cards. I used Google Colaboratory's GPU acceleration to train this model; Fourth, the viewer-participant. The crux of this piece is in its interaction, and it would cease to be if not for the participant and their own assumptions about the world; And lastly, me, the artist. I feel like I just gave the above elements a focal point in which to materialise. All these elements are intertwined - the neural nets wouldn't have been implemented if it weren't for the powerful GPUs, and I wouldn't have been able to implement this piece if it weren't for Google's open resources. The sociopolitical bias that the data carries is unfortunately reproduced in the program's output. I see them collectively as a creative system in its own right, producing and reproducing different knowledges and biases(Cox, 2016). My job here was to imbue it with my intention - and I feel that it turned into something much more complex, probelematising my preconceptions along the way.
Reflection
That's the main body of my report. I'll finish it with accounts of how people responded to this piece. Generally speaking, they were quick to anthropomorphise the program. One participant commented "it knows everything about skin tones and hits it out the park with that, but it's not too sure about hair. It has a go... but it's like a kid just using their favourite colour when they don't know what colours things are." The skin tone issue aside, the analogy of him drawing a face and the program "drawing back" is kind of sweet. No matter how non-human something is, we just can't help but do this - but there's something in that. Maybe the in order to imagine how a thing perceives(Bogost, 2012), the quickest route is, counter-intuitively, to imagine the thing as a human.
Many participants remarked that it felt like a game, or a conversation between them and the program. One of them would wait to see "how the program perceives [their] drawing," and decide what to add in response. Their choice of word "perception" made me happy, I must admit. They later commented that it was like a game of exquisite corpses, and that it was a "weird experience... because, you know, whose drawing is it?" This comment was what made me think about creative ownership.
I'm glad that they thought it was fun, but they did not necessarily see what I saw. Maybe next time, I can make work with the intent to draw attention to the techno-cultural networks and how knowledge is produced and reproduced, by deliberately using certain kinds of datasets. For example, Google Image search for "black teenagers" and "white teenagers" return vastly different results; mugshots for the former, and a happy group of teenager for the latter(Cox). I would have liked to end this report on a lighter note, but here we are. The cultural and political entanglements of the network really made me think about how to choose and use data - now I feel compelled to make GAN art with some sociopolitical substance, which I've not seen done yet.
References
Amaro, Ramon. (2019) “As If.” e-flux architecture vol. 97. Web. https://www.e-flux.com/architecture/becoming-digital/248073/as-if/
Barthes, Roland. (1967) Aspen, no. 5–6.
Brooks, Rodney, and Steels, Luc (1995). The artificial life route to artificial intelli- gence: Building embodied, situated agents. Hillsdale, NJ: Erlbaum.
Brooks, Rodney. (2018) "Steps Toward Super Intelligence" Web. https://rodneybrooks.com/forai-steps-toward-super-intelligence-i-how-we-got-here/
Bogost, Ian. (2012) Alien Phenomenology, Or, What It's like to Be a Thing. London: U of Minnesota.
Cox, Geoff. "Ways of Machine Seeing" (2016) in Unthinking Photography. Web. https://unthinking.photography/articles/ways-of-machine-seeing
Guckelsberger, Christian, Salge, Christoph, and Colton, Simon. (2017) "Addressing the "Why?" in Computational Creativity: A Non-Anthropocentric, Minimal Model of Intentional Creative Agency".
Maturana, Humberto R., and Francisco J. Varela.(1992) The Tree of Knowledge : The Biological Roots of Human Understanding. Rev. ed. Boston: Shambhala
Merleau-Ponty, Maurice. (2002) Phenomenology of Perception. London: Routledge Classics.
Suchman, Lucille Alice. (2007) Human-machine Reconfigurations : Plans and Situated Actions. 2nd ed. Cambridge: Cambridge UP.
Technical References + Dataset
Atken, Memo. webcam-pix2pix-tensorflow. https://github.com/memo/webcam-pix2pix-tensorflow
Berg, Tamara. Faces in the Wild dataset. http://tamaraberg.com/faceDataset/index.html
Hesse, Christopher. pix2pix-tensorflow. https://github.com/affinelayer/pix2pix-tensorflow
Isola, Phillip. Zhu, Jun-Yan. Zhou, Tinghui. Efros, Alexei A. pix2pix. https://phillipi.github.io/pix2pix/