




























































the Unknown Person
The Unknown Person is a screen-based installation that connects a piece of the artist’s family history to Britain’s post-colonial reality. Using machine learning processes and facial recognition algorithms, the piece interrogates the gaze of surveillance and social control systems through liminal spaces in the city.
produced by: Eddie Wong
Introduction
In 1949, my grandfather left his family and disappeared into the Malayan jungle to fight the British as a communist guerrilla soldier. After three years of violent rebellion against the armed forces of the British colonial government, he was shot and killed. My grandmother and her children witnessed from afar and in silence how his body was dragged out to be displayed in public. Under the threat of arrest and execution, my grandmother had to deny relations with the deceased when forced to recognize the corpse. Subsequently, my grandmother escaped with five children in tow and became fugitives of the law. These three incidents in my family history formed conceptual structure of the piece.
The Unknown Person interrogates the tension inherent in living in a highly scrutinized world to craft a personal narrative that connects Britain’s violent colonial past to a piece of my family history. What are the parallels between the surveillance and recognition systems of today to the rebellion that the artist's grandparents have lived through and perished? The work reimagines what the machine's gaze at an 'invented person' ingested into a data form might look like. By exploiting neural network processes similar to those in surveillance detection systems, I situate myself at liminal spaces within the City of London – a symbolic zone of post-colonial reality and subsequently redacted myself from its surface.
Concept
The starting point of the work was when I wrote the final term essay The City as a Fictioning Machine for Research and Theory module. I researched on the City of London as a ‘fiction-generating machine’ and hypothesize that the City could be considered as a complex piece of algorithm. I situated myself and my family history from a postcolonial perspective to explore how family narratives are woven.
How can I play these tensions off another – my family's narrative and the city's'? And how can I use computational techniques to bring to life this going back and forth? I decided on the story of my grandfather's communist guerilla activities and my grandmother’s survival in the aftermath. I wanted to establish a link between the surveillance and recognition systems of today to that of my grandparent's time. My grandmother could be seen as a single data point who denied recognizing the corpse of her husband. She defied and refused the optics of state-machines and was able to survive. Would it be possible for her to survive in today’s ultra-scrutinized world? To refuse the all-seeing eye of an Artificial Intelligent dragnet, that can collect, track and control infinite data points on a single individual and all his/her relations?
The driving motif of this piece is optics. I wanted to play off the tension of who’s watching whom and who is being watched through what means in a culture of hyper-surveillance. Optics are present throughout my family narrative too. The colonial government sees my grandfather as a terrorist, the anecdotes of his death and grandmother’s survival are from eyewitness anecdotes and of course, the visible/invisible appearance of my grandfather. This motif is expressed visually in the final output of the film.
The City of London in the piece was a character in itself that observes through its security cameras as well as an implied passive observer of the British Empire's history. From a post-colonial and cultural studies perspective, the cultural theorist Homi Bhabha refers to the liminal having the potential to be a disturbing influence. “This interstitial passage between fixed identifications opens up the possibility of cultural hybridity that entertains difference without an assumed or imposed hierarchy” (Bhabha 5). Therefore, I have chosen the liminal spaces within the City to situate myself as a disruptive wedge at the in-betweenness of the City’s entanglement with Britain's post-colonial reality. The scaffolding in the final installation was the physical representation of the City as a process that generates this reality. In a literal sense, the scaffolding is a latticework that holds my family stories.
I filmed myself having a phone conversation with family members back home recounting the incidents of my grandparents. Using a combination of neural network and object detection processes that are similar to the ones used in the surveillance mechanism, I’ve redacted myself and then fill myself back into the surface foregrounds the tension found in liminal spaces at the threshold of the surveillance apparatus of the city. The flickering pulses from infrared security systems are made explicit, while I become a subject of surveillance, whose specific objectivity is subsumed and ingested into the data form - rendering the self as a smear across the City’s surface, a ghostly embodiment of my grandparent’s stance of refusal.
Background research
Machine Learning
I’ve been interested in what Machine Learning (ML) could generate since I’ve experimented with Generative Adversarial Network (GAN) by playing with the pix2pix repository for my Research Project last year. I knew I wanted to continue to experiment with Machine Learning and do something with the aesthetics of this project. The research informs the visual design of the piece as I wanted to play with the idea of reflection, extraction (reflecting on the extractive capitalism of the City). From working with GAN, I was fascinated with its visual potential that is suggestive of the erasure of space/time boundaries. This duality fits in with the narrative material but I wanted something other than the generative and hallucinatory feeling that GAN outputs.
For the initial visual design of the film, I wanted to keep in line with the "look" of machine learning surveillance systems such as facial recognition and object detection to inform the design of the images. I played with object detection models such as YOLO and face detection models. The Machine Learning technology that I’ve implemented isn’t particularly novel per se. I first came across an experiment by Chris Harris where he uses A.I to detect and then remove vehicles from the street. Another artist Mikhail Rybakov had done tests using A.I to delete bodies. He combined two open-sourced GitHub repositories MaskRCNN for body recognition and Generative Image Inpainting with Contextual Attention to fill back in the gap. When I contacted the artist personally to ask him more about these tests, Mr. Rybakov was graceful enough to offer me some tips on workflow.



Video
Lisa Rave’s Europium was a great inspiration to how I can structure the stories of contemporary concerns of a larger colonial legacy and its lasting impact on the environment. She masterfully weaved through family narratives, extraction of natural resources and interlinks these narratives giving each their own space and context, but she also often returns to the spiral of a nautilus mollusk as a driving motif.
I've had reservations about working with video as a medium. Being on a computational course, I felt the need to make things...computational. However, video art has its place in the art world and there some great machine learning videos out there. In this case, the narrative material of my family story drove the medium. The final piece took the shape of a series of fragmented video essays, which reflected on the fractured nature of how the stories were recounted and remembered. I felt this to be the best, if not the only way to tell the complicated story of my family. The cinematography was crucial to express a sense of liminality. The location choices, each has its historical significance and provided the post-colonial subtext to the narrative.
Technical
Machine Learning
For the machine learning model, I first experimented with installing the MaskRCNN and InFill Painting GitHub repositories. The tutorial series and repo by Mark Jay was an immense help in getting started (Mask RCNN with Keras and Tensorflow) with some early test shots on still images and videos. Although I successfully got the model up and running on the local GPU, it struggled to run smoothly on my machine. As well as that, the model outputs one frame per- second video which was not as impressive to look at.
After extensive experimentation and research, I decided on alternative models to create a similar effect. I relied heavily on the remote GPU and model libraries of RunwayML. The platform provided more models and flexibility for the workflow of producing image sequence files. I decided to use the Deep Lab model by Gene Kogan to extract semantic maps from objects in images. The model was able to capture multiple objects at various scales based on COCO-Stuff 10k/164k and PASCAL VOC 2012 datasets. In my case. I only needed inference from a single image– that of a Person. The model saves a black and white mask out of the image which I then used as a source for segmentation input for the image inpainting task. For that, I've used the Deep Fill model by feeding in the black and white images generated from Deep Lab as segmentation input to fill the missing regions of the image (footage of myself). The model comes pre-trained on the Places2 dataset by MIT which contains a lot of images of outdoor places. I hoped, therefore, it would be able to bias the filling in of the 'Person's' image towards more natural scenes of its surroundings.
One of the challenges with the image inpainting algorithm was the low-resolution output. I needed the output to be relatively high res as it will be displayed on video monitors. The dataset came pre-trained with images of resolution 256 x 256 and the largest hole size 128x128. Above that, the image resolution deteriorates. I was a concern with the pixelation of a 360p video when broadcasted on large monitors. I had to do an upscaling pass from 360p back to 720p and then adding it back to the original image information and mask. That way I kept the original quality everywhere except for the infilled area, and the infilled area is smooth and a bit blurry.
The end result was satisfactory. The paints me out with imperfectly but that adds to the visual potency, otherwise, perfect invisibility meant there would be nothing to see! It posed the question – am I a figure hiding from the gaze or has the camera penetrated even the liminal spaces? The ambiguity brought to life the back and forth of the tension between the self and the story while revealing the liminality of the space.


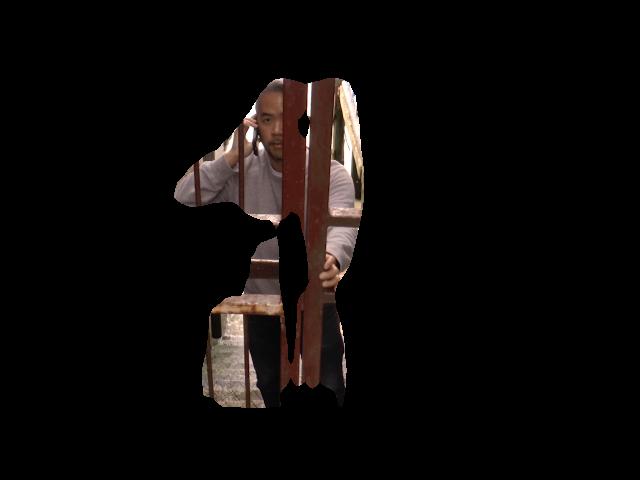


Interaction – Face Detection
For the interactive component of the piece, I revisited the final term assignment for the Workshop and Creative Coding. I built a face-detection algorithm in Openframeworks and modified the OfxFaceTracker2 addon by stripping the wireframe face-track mask down to its bare minimum and ran it on webcam feed. The addon is based on dlib’s face detection API, that generates the various facial landmark (eyes, nose, mouth etc). My approach was to design the ‘visual look’ that is suggestive of a facial dataset used face detection algorithm used in machine learning training.
One of my concerns with the implementation of an interactive element in my overall piece was that it may seem to the audience (and examiners) to be superfluous. There are two reasons why I’ve added interaction to the piece. On a conceptual level, the webcam feed that is detecting faces on the piece implies that the City’s surveillance apparatus is observing. The viewer then becomes complicit in the system of surveillance and control. On a practical level, it was designed with the final scaffolding structure in mind, so that it draws the viewer into walking around the structure, hence bringing forth the multi-dimensional qualities of the structure. The label on the bounding box around the face-detection mask says "Unknown person". It implies a failure of the machine to label an object. At the same time, the Unknown Person could be just anyone. One of the main challenges I’ve faced was running Openframeworks in Linux mode on a Rasberry Pi. The face-tracker addon was apparently incompatible with the Pi’s operating system. For the exhibition, I had to run the face-detection component from my laptop, which, fortunately was without any issues.


Installation
The installation ran on 6 x monitors, 4 x Raspberry Pis configured to play video upon booting and controlled via SSH, a laptop running the face-tracking code on OpenFameworks, a wide-lens webcam for camera input. I relied on this video looper code from Adafruit tutorial to play movies off of USB drives when inserted in the Raspberry Pi. It calls on the default video player for Pis, omxplayer and can play most videos encoded with the H.264 video codec and in a video format .mp4 format. This is the best solution for my situation because omxplayer will use the Pi's GPU (graphics processing unit) to efficiently play videos that are 720p and even 1080p.
The piece's scaffolding structure measures 8 ft by 7 ft high, an industrial scaffolding. I attached six monitors with cable ties. The monitors (courtesy of tech office) were reappropriated from recycles. The stripped-down, bare metal look adds to the aesthetic value to the piece. My main challenge for the installation stage was mainly working with the scale of the scaffolding. Due to the thickness of the bars, I had to custom fabricate brackets for each of the screens to attached it to the bar. This was not possible due to time constraints as well as the lack of screw holes at the back of these monitors because they had the frames removed. I found an efficient way was to secure the screens by threading the cable ties through the monitors and over the bars. Somehow, that held the screens up although it may not the most elegant solution.




Future development
The future development for this work is currently in progress. I am speaking with performers and a VJ on collaborating to use the machine learning techniques on this piece as a starting point for their own work. The natural next step would be experimenting with deep learning models trained with a smaller, tightly curated dataset. For example, I’d like to try redacting more specific objects such as building types and filling them back in with a trained model from the dataset. I’d also like to develop explore the redacting images in real-time via a camera feed, perhaps in combination with the face tracker algorithm on OpenFrameworks.
Another aspect that I’d like to play within RunwayML is to chain three models together – perhaps the third one being a GAN that fills in the gap. It’d be interesting to see how a neural network works when feedback against itself. I aim to present this work at an ML or related creative technology conferences and show this work, at a smaller scale in at least one exhibition. I’d like to keep learning more about deep learning algorithms and how it’d be used as a storytelling medium in itself. I think it’s important to offer an alternative approach to using ML amidst the increasing democratization of ML tools. On a professional level, the City of London is a fertile ground for investigation in the context of post-colonial liminality. I will pursue this research independently or academically moving forward.
Self-evaluation
Overall, I am pleased with the aesthetic of the neural network redaction effect for the videos. When juxtaposed against the imagery of the City of London, along with the text of my family narrative and displayed on a large scaffolding structure, the piece evoked an otherworldly sense of awe and drama which was as surprising as it was satisfying. A student from the filmmaking course commented that it was ‘strangely immersive and cinematic’.
I felt that the piece delivered on a conceptual level. The structure of the scaffolding succeeded in representing the imposing and impersonal nature of the City. The placement of the screens within and around the scaffolding structure gave an impression of a security control room. This goes back to my initial aim of playing off several large, complex themes with one another (self, machine, place). In the end, the story of my family 'came through'.
The outcome of the installation piece was generally well-received but it was not all according to meticulous planning. On a practical level, the scale of the scaffolding was a massive undertaking (literally speaking!). There were times when I felt that I was entering stage-setting work on a film set, which I was not equipped to handle. The number of monitors and Raspberry Pis proved to be difficult to set up and managed. I could also have used a variation of screen sizes to give the overall piece a better visual quality. Due to limited resources (all the screens are recycled), this was not possible. One of the screens died but the presence of a failed piece of electronic resonated with the sombreness of the story. The face tracking component might have seemed slightly out of place. This was remedied by placing the interaction screen inside the scaffolding so the viewer had to peer inside the structure to interact with it. The code could've been developed further. For instance, having each face leave a trail on-screen and eventually accumulating to fill it up would be quite interesting. Additionally, I could've included a code that stores an image each time it detects face so I can keep track of who has interacted with it.
The making of this piece has stretched my technical limits. When I came on the course with no coding experience to speak of, I wanted to explore machine learning, learn how to make art with code and was (am still) interested in storytelling. From that point of view, I have met all my educational goals in this course.
References
Code
Deep Fill – http://jiahuiyu.com/deepfill/
Deep Lab (Gene Kogan) – https://github.com/genekogan/deeplab-pytorch
Generative InPainting (Jiahui Yu) – https://github.com/JiahuiYu/generative_inpainting
Mask RCNN
Mask RCNN Repo: https://github.com/matterport/
Mask RCNN paper: https://arxiv.org/pdf/1703.06870.pdf
Mask RCNN with Keras and Tensorflow (pt.1) Setup and Installation
Mask RCNN with Keras and Tensorflow (pt.3) process video
OpenFrameworks Face Tracker
http://dlib.net/cnn_face_detector.py.html
https://github.com/HalfdanJ/ofxFaceTracker2
Raspberry Pi Video Looper
https://learn.adafruit.com/raspberry-pi-video-looper/usage#tips-for-looping-videos
Research
Bhabha, Homi K. The Location of Culture. London: Routledge, 1994.
Lisa Rave, http://wholewallfilms.com/europium/