




























































Leave to Remain
The English language is woven with threads from beyond British borders. In contrast to the fluidity of the language and its complex ancestral lineages, the UK's borders are becoming more rigid and restrictive. This book was created computationally with a program which can be used to visualise the 'etymological flavour' of a text and to somewhat facetiously ascertain its given 'Englishness'.
produced by: Marisa Di Monda
The Project
The story of the Modern English language is one of migration, invasion, absorption, colonial expansion and hybridisation. In the grand scheme of things it is still a young language. Although officially classed as a Germanic language it has drifted and morphed over the centuries to a point where it has very little mutual intelligibility with its neighbouring Germanic contemporaries. In its current form its lexicon is comprised largely from 'borrowed' vocabulary from diverse linguistic origins. Each word in the English language has a story. Each word has been on a 'journey' of sorts. These 'journeys' can be uncovered by studying a word's etymology.
This book was created computationally using Processing and the Merriam-Webster Dictionary API. The program collects the etymological forms of each word from a provided text. The provided text in this case is: 'New immigration system: what you need to know', sourced from www.gov.uk. Each etymological form, such as Greek, Latin, Middle English etc. is represented by a different graphic. A key explaining the graphics is printed on the last page.
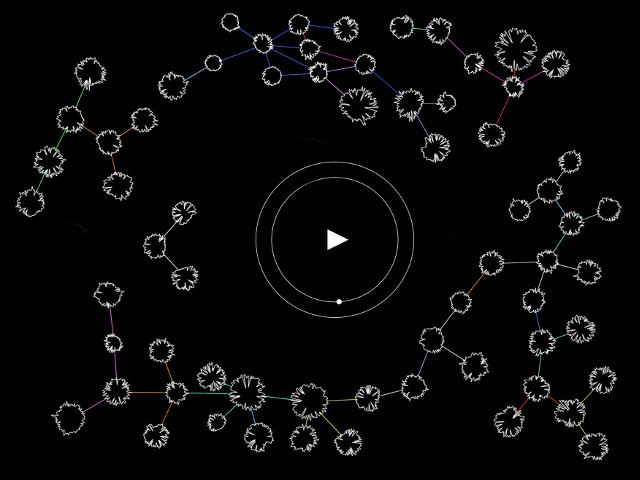
Firstly, each word is visualised by overlaying the graphics of each etymological form attributed to the word, one on top of the other. The more linguistic permutations a given word has historically occupied, on its journey to its current form in Modern English, the more dense the pattern. The following page is the corresponding text written in Latin characters. The text is run through the program a second time but this time reveals only the words that are left when everything but those of 'purely British origin' are left out, that is words that have no lineage other than Modern English, Middle English, Old English, and the languages indigenous to the British Isles.
The UK has begun the process of a major overhaul of its immigration policy in order to more strictly control who is able to enter and inhabit the British Isles. It is designed to reduce the flow of overseas nationals into the UK, the consequences of which will in turn reduce the freedom of movement for its own citizens outside of the UK.
Technical
This program creates an A5 pdf book. This book was created computationally using Processing and the Merriam-Webster Dictionary API. From the API, the program collects the etymological forms of each word from a provided text.txt document. The provided text in this case is: 'New immigration system: what you need to know', sourced from www.gov.uk.
The first step is to retrieve the etymological information from the API's json. The "et" key provides a string. Sometimes, for information to be retrieved the word that is sent to the API needs to be cleaned or adjusted beforehand:
- Punctuation is removed from strings
- Using regular expressions strings are checked for numbers and acronyms and in this case are not sent to the API. Dot points and hyphens are also not sent to the API but kept as they are.
- If the word pulls a string that does not give etymological information but refers to another word then that word is checked in the API.
- If after these checks the word still does not pull an "et" key then firstly suffixes are removed.
- If this doesn't work the stem word is retrieved from the API. It checks the first two stem words in the list. If these words still do not pull the et key.
- If still nothing is returned then the word is assigned "unknown".
- The words assigned "unrelated" are those that return an "et" with someone's name.
It's a tedious process due to the way the API formats it's information. Unfortunately, text libraries such as RiTa would not have served my purpose.
The program has 3 runs:
- Firstly, each word is visualised by overlaying the graphics of each etymological form attributed to the word - meaning, each form found in the "et" string. After the page is full the run switches to the Second Run.
- The second run starts a new page and draws the words that were previously printed as graphics as their usual latin characters in black. The program alternates between the first and second run until they have run through the lines of the text. This allows the reader to flick between the graphics page and the text pages to see which words have produced the etymological pattern because the formatting is the same on both pages so they match up.
- The third run only draws the words in black that have an etymology form that only corresponds to the English category and NO others. The formatting of the text is again the same as the previous two runs.
I printed, cropped and perfect bound the book at home. The graphical pages of the book were printed on tracing paper to allow for the corresponding words on the following page to show through slightly.
The aesthetic of the graphics was unconsciously influenced by the artist Manfred Mohr. In particular his black and white iterative works that resemble hieroglyphics.



