




























































Additive TV
produced by: Taoran Xu
Introduction
Additive TV is a video installation equipped with a computer vision system. Instead of making your facial expresions change during the watching time, it requires you to sustain spcefic facial expression in order to keep watching same video clip. This project grew out from experimenting with facial recognition and video manipulation.
By default, the video content displayed in the monitor is a mixture mixed with other two individual videos including their soundtrakcs. The two videos are jammed and playing together which creates a montage-like effect from vision. It distorts its audience to recognize the reality of each video. The facial expression is being captured by the camera at the same time.
When the audience is smiling and captured by the camera, the content of the monitor will change and play one of the two videos only including its sound track; When the audience's mouth is in 'O' shape and captured by the camera, the content of the monitor will change and play the other one including its soundtrack; If the facial expression is recognized neither as 'smile' nor 'O' shape then the monitor play by default setting.
Technical
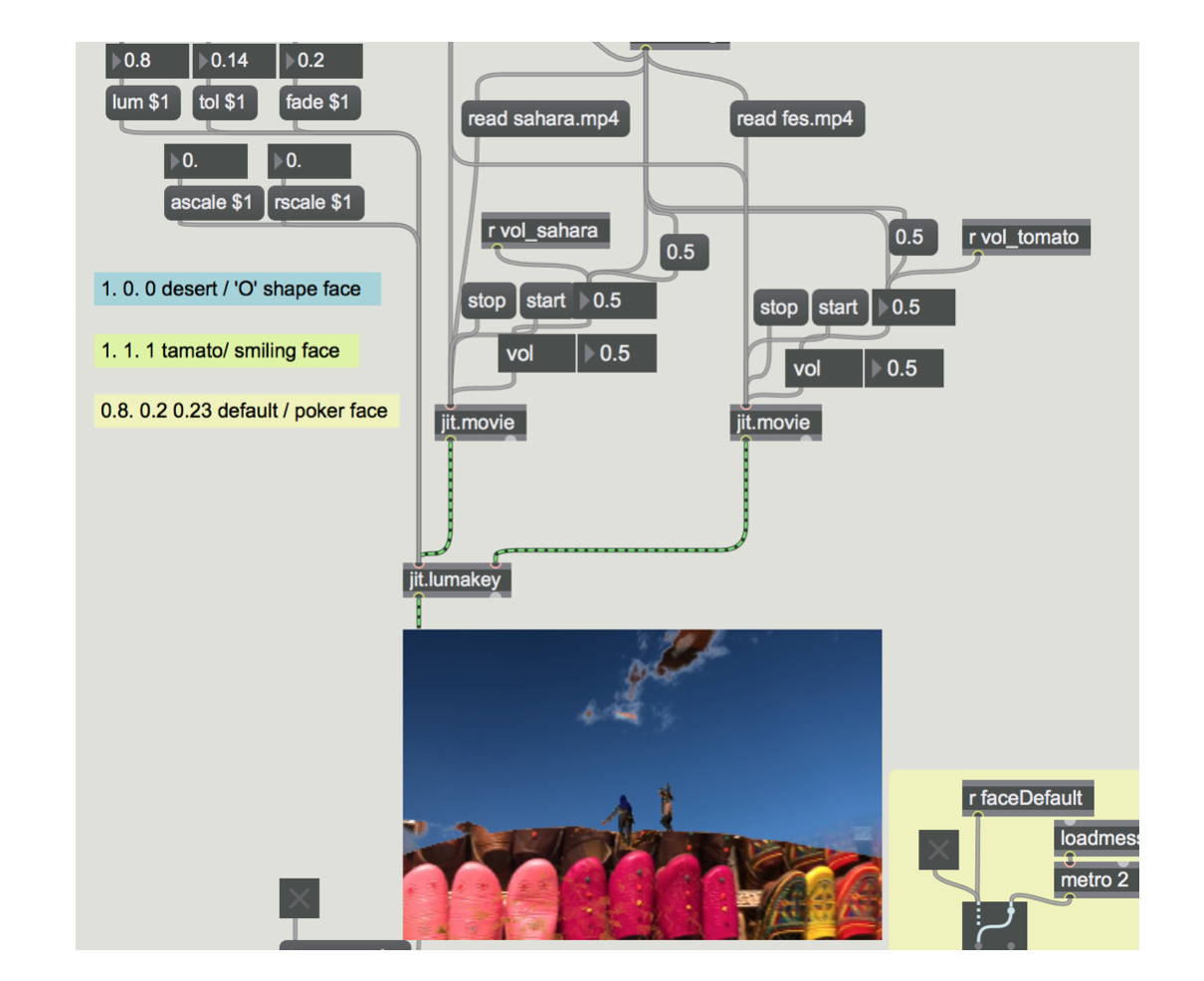
The camera feed is analysed via Kyle McDonald’s FaceOSC, which scans your face and extract the key joints of your face and send the analysis results like mouth width and heignt via OSC to any application that supports OSC. In this project, FaceOSC sends messages to my Max/MSP/Jitter patch and processed in real-time. In order to determine the facial expression wether it is a smiling mouth or 'O' shape mouth or any other I use mouth width , mouth height and the ratio between the mouth width and mouth height .

As for video processing, I use the lumkey object of Jitter to conbine two videos together with specific parameters setting. The video clips I chose in this project are captured during my trip in Morroco. One is at the Sahara desert and the other one is in a leather store locates at the old city in Fes.
By defualt, the $lum is 0.8, $tol is 0.14 and the $fad is 0.23. The volum of each video's is set its 50% maximum.
If it is a smiling face, plays Sahara video clip only, the $lum is 1.0, $tol is 0. and the $fad is 0. The volum of Sahara is set its 100% maximum and 0% for video clip of Fes leather store.
If it is a 'O' shape, plays video clip of Fes leather store only, the $lum is 1.0, $tol is 1.0 and the $fad is 1.0 The volum of Sahara is set its 0% maximum and 100% for video clip of Fes leather store.
Conclusions
This project grew out from experimenting with facial recognition and video manipulation and is potential for further development in the future.
a) More video feeds can be added together even live camera feeds. And due to the capacity limitation I can only submit my project files within 100 mb, but in real presentation I can use longer videos instead.
b) Instead of making classifiers,making regressions between each facial state would be more challenging and fun.
c) Audio signals can be processed in a more complex and interesting way.
d) Presenting the project in a more artistic way, instead of showing it in a laptop could make a real TV set installation.