




























































Whether red is indeed blue?
produced by: Marlena Kepa
Introduction
Humans are able to recognize various objects, shapes, styles, forms, colors, structures etc. Regardless of whether a given thing is physical, in a picture or in a drawing. We are able to determine whether a giraffe is indeed a giraffe or a drawing of a giraffe made by a 5-year-old child. However, despite rapidly developing technology and newer and newer algorithms, these are not able to replace human perception in the above-mentioned matter. Something that could seem downright trivial to a human, is not for recognition algorithms (Boulton, Hall, 2019).
Machine learning and model training can have a significant impact on results that can be used in a variety of fields that surround us everywhere, i.e. medicine, finance, banking, art or social media. Also an inadequately trained model can have a really negative impact on final algorythmic results.
As in the topic of this work 'Whether red is indeed blue?', a poorly trained model in this case may contribute to the bad evaluation of the algorithm and classify blue as red and vice versa. On the other hand, we should treat an algorithm as a child of several years who learns to notice the differences between an apple and a pear, or a dog and a cat based on clear pictures and terms. Despite the fact that this child is probably able to recognize the difference between a distorted pear and an apple, the algorithm will probably recognize this pear as an apple.
So, in our daily life should we fully rely on the results that the machine uses? What could be done to improve the recognition and classification results?
Perception differences between man and machine.
Deep neural networks (DNNs) show satisfactory results in diagnostics based on photos or recordings, but can we trust them? Along with the modification of databases, the efficiency and perception of algorithms can dramatically decrease, while the human perception will still remain the same. Therefore, every time we train our model, we should be able to distinguish the difference between human and machine perception (Makino,2020).
For people who can identify colors, structures etc. red will always remain red, regardless of whether it would be red, closer to orange or pink. We can also refer to the theme of Wittgenstein's Philosophy and the concept of color where people are able to distinguish the colors immediately, without physical contact (Park,1998). Despite the fact that it might seem that the same applies to algorithms, it unfortunately only depends on what database the trained model contained during the training.
In cases where the data is not clear or too similar to each other, the algorithm will suffer a decrease in performance.
The data used in training could be very clear to the person who collects it, while the interpretation of the data through the algorithm is completely different.
As of today, the detection of objects is based on deep learning and the latest algorithms, which significantly improve the detection rate year by year. Conversely, model training steps still require a large database, and lowering the value of the data may reduce the performance of the algorithm (Kim, Lee, Han, Kim, 2018).
In most of these cases, if the form that the algorithm is trying to recognize is even slightly different, we can observe a series of erroneous detections or classifications.
So what could be done to improve the recognition results?
Traditional methods used to detect have been trained on static objects from photos where the background surrounding them has been subtracted. However, with the movement of the object, irregularities may be read. Consequently the best course of action in this case would be to train the model on moving objects. And although the above method is already used, along with the use of the model in a video in which too much is going on, objects may not be classified correctly.
Convolutional neural network models when used by CCTV show lower performance due to different angles, inclination, color or quality which can differ (Kim, Lee, Han, Kim, 2018). In this case, the best procedure to avoid any irregularities would be to train the classifier for each type of the cameras used.
The big disadvantage of the current methods of recognition and detection of objects is also the omission of smaller and hidden objects. In this case, the most common reason may be bad lighting, for example a person who is partially behind another object.
Classification and object recognition in art.
Machine Learning surrounds us in everyday life. We can see it used in medicine, finance or social media, as well as a huge number of algorithms that are also used in art.
The question is, in this case, is input or output an art?
Klingemann, when being interviewed about one of his works (Memories of Passersby I, Klingemann), said that ‘the art is not the images, which disappear, but the computer code that creates them’ (Benney, Kistler, 2019).
In this case, I absolutely agree with Klingemann, because the code he had to create to use in his work had to be really refined like an oil painting painted in layers day after day. However, I believe that we can not make such a statement in every case. Despite the fact that in Klingemann's work, generations are not predictable and may create seemingly strange portraits with time, they are not caused by incorrect code or contained databases. Similarly, we can also refer to the works of Trevor Paglen and his well-known exhibition ('From Apple to Anomaly), where he presented a form of computer vision.
On the other hand, what if the algorithm contains a reduced data value and shows an erroneous assessment of the situation and with these errors we can get unexpected and surprising results? I believe that in this case, output is art!
My attention is also attracted by the sculpture that consists of two neon brackets (Classification.01, Mimi Onuoha) from 2017. The artist used classifications using brackets, which use a nearby camera, deciding that viewers were classified as similar. In this case, the viewer should guess for himself why the brackets light up and classify as similar, or did not work. On the other hand every human also classifies, and thanks to such a work of art we can get closer to technology and understand the classification of machines.
Artefact
As an artefact, I created a video that shows some examples of imperfections of models in various situations.
Object detection
The first example uses a CocoSsd pre-trained model (Single Shot MultiBox Detector) and live recording from a webcam. In the recording, I used several objects, such as an apple, a pear, a banana, a lighter, a pen or drawings of a banana and an apple.
On the video, we can observe that as the angle of inclination changes or the object is moved, the detection recognizes the object, showing a list of incorrect classifications. In the case where I used a real apple and a drawn apple, the drawn apple has not been recognized at all.

However, despite the same situation with the use of a banana and a drawing of a banana, the detection classifies both objects as 'banana'.
This inaccuracy is called the Cross-depiction problem (Cai, Wu, Hall, Corradi, 2015). It consists in recognizing and classifying objects, regardless of whether they are presented in reality, in a photograph or whether they are drawn elements. The algorithm is not able to imitate a human eye and distinguish objects presented in different forms. And although in the case of apples the algorithm did not classify the drawn object at all, in the banana example it is immediately convinced that it can recognize two fruits (see below).

Other classifications of a banana include a number of incompatibilities, such as being recognized as a skateboard or a hot dog.
On the other hand, the pear example in theory should not work at all, because this fruit is not on the Coco model's list of categories, however, a pear has been classified as an apple, a teddy bear, donut, or orange. Similarly, with a lighter or a pen, which are also not in the category list, and yet the objects were recognized as a knife, bottle, Frisbee, cell phone, baseball bat or scissors. The result of these errors is a largely insufficient database. Nevertheless, the calculations try to recognize the object and match it with the classification closest to it.
Image classifier & Sound Classification
In the second case, using the sound and image classification of the four primary colors, i.e. red, blue, green and yellow, I decided to erroneously train the model containing the color photos. The data that I used for this training is completely incorrect, but I decided to use the sound classifications in the correct way. Thanks to this, I wanted to check and present an example in which incorrect data, even in the simplest examples, can negatively affect the final results that we are trying to achieve with the implementation of the project or artistic work.

Object detection
For the next example, I decided to use the real-time object detection system using YOLO or CocoSsd pre trained model.
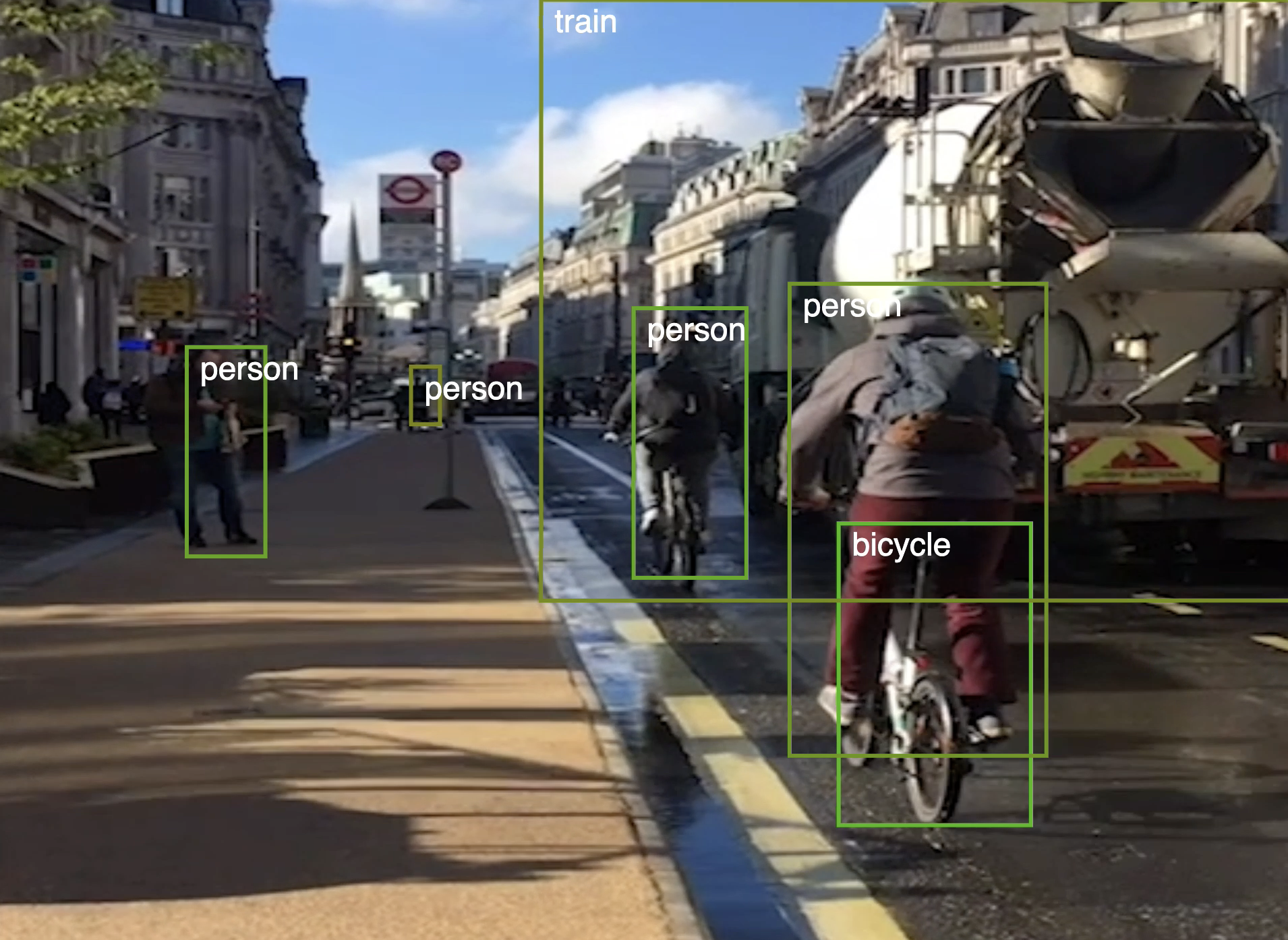
In the photo below I’m using the Coco model, which includes 90 different categories of objects. Unfortunately, the algorithm classified a truck as a train, despite the fact that in the categories we can find the 'truck' classification.
Part of the table showing the categories of objects in the CocoSsd model. (see below)

Similarly, we can also pay attention to the fact that the algorithm also omitted many other small objects, such as people in the background, bus or road signs. In the second stage of this example, in the same video, I decided to use both models and check the differences between incapacities and the number of objects identified. The CocoSsd model shows much better results, but still omits many objects.

YOLO pre trained model CocoSsd pre trained model
Object detection with style transfer
Analyzing a similar scenario, but with the use of style transfer and a pre-trained model (trained on the basis of the oil painting of Francis Picabia's ‘Udnie -Young American Girl, The Dance’, from 1913), we can refer to the Cross-depiction problem (Cai, Wu, Hall, Corradi, 2015).
The model in this case clearly shows a decrease in performance, and although it recognizes objects regardless whether they are real or ‘painted’, it also ignores many objects that the human eye can perceive.

Sound classification & image classifier in different scenarios.
For the 5th example with image recognition and sound content, I trained two models using the Google Teachable Machine. I decided to use different sounds and pictures of 4 different birds ie Blackbird, Great tit, Raven and Sparrow to check the results. As I suspected, at the moment when in the recording we have a mix of sounds, the algorithm begins to show incorrect results. The sound classification of the Great tit classified it as a raven or a sparrow, and the sounds in the background as the raven, although it should have qualified the sound as background noise.

FaceAPi
Similarly to the artistic example of CV Dazzle (Harvey, 2020), which studies how modifications or camouflage can be used in face detection technology, I decided to conduct two similar experiments. I used the API that was created by ml5. js open source, that allows access to face detection and 68 landmarks.
One with face painting and adding a few geometric shapes in Adobe Photoshop, the other with filters available on Instagram.

The filters I have chosen age, duplicate the features, modify or add some elements to the user's face. To my surprise, faceApi did quite well in this case. However, despite several unrecognized photos, I am fully surprised that with the use of a filter that duplicates the eyes on my face, I was classified as myself, but when I have small flowers on my face and a light make-up that slightly distorts my eyes, faceApi did not recognize my face.
Conclusion
Based on the presented experiments, we can conclude that in most cases, despite satisfactory data, algorithms can fail even in the simplest way. One element (applying objects, sound, another filter or makeup) is enough to get a series of erroneous classifications.
However, despite the many irregularities I have presented, I believe the machine learning ability is amazing and continues to grow. Probably in a few years, as technology improves, these problems will be meaningless. I believe that the algorithms will be more detailed and wont have an issue with correct classification and recognition of elements or objects regardless of given form ( physical, drawn, photographed or painted).
In addition, we have to remember that behind each of these mismatches, there is a poorly trained model, and low-value data behind it. On the other hand, a human or certain algorithm is responsible for collecting data that is then used to train new models.
To sum it up, neither algorithm nor human is infallible. Considering the differences between man and algorithm perception, for the time being results should be double checked with attention to above matter.
Bibliography
A hybrid framework combining background subtraction and deep neural networks for rapid person detection Journal of Big Data, Chulyeon Kim, Jiyoung Lee, Taekjin Han & Young-Min Kim, 2018,
[online] Available at :https://journalofbigdata.springeropen.com/articles/10.1186/s40537-018-0131-xPhenomenological Aspects of Wittgenstein’s Philosophy, B.-C. Park, 1998,
[online] Available at: https://link.springer.com/book/10.1007/978-94-011-5151-1#authorsandaffiliationsbookWhat Object Categories / Labels Are In COCO Dataset?, 2018,
[online] Available at:
https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/?fbclid=IwAR06d-t6J3Come8vwX_uIQ8AGlhBCXMojDr77SEX0l16C909F-mCW7igXt8Artistic Domain Generalisation Methods are Limited by their Deep Representations, Padraig Boulton and Peter Hall, April 2019, [online] Available at: https://arxiv.org/pdf/1907.12622.pdf
Differences between human and machine perception in medical diagnosis. Taro Makino, Stanislaw Jastrzebski, Witold Oleszkiewicz, Celin Chacko, Robin Ehrenpreis, Naziya Samreen, Chloe Chhor, Eric Kim, Jiyon Lee, Kristine Pysarenko, Beatriu Reig, Hildegard Toth, Divya Awal, Linda Du, Alice Kim, James Park, Daniel K. Sodickson, Laura Heacock, Linda Moy, Kyunghyun Cho, Krzysztof J. Geras, 2020, [online] Available at: https://arxiv.org/abs/2011.14036
The Cross-Depiction Problem: Computer Vision Algorithms for Recognising Objects in Artwork and in Photographs, May 4, 2015, [online] Available at: https://arxiv.org/pdf/1505.00110.pdf
Citation
AIArtists.org, Mario Klingemann, by Marnie Benney, Pete Kistler, 2019
[online] Available at: https://aiartists.org/mario-klingemann
References
Computer Vision Dazzle Camouflage, Adam Harvey, 2020,
[online] Available at: https://cvdazzle.comFaceApi, ImageClassifier, StyleTransfer, ObjectDetector, SoundClassification, Ml5.js
https://learn.ml5js.org/#/AIArtists.org, Mario Klingemann, by Marnie Benney, Pete Kistler, 2019
[online] Available at: https://aiartists.org/mario-klingemannMimi Onuoha Classification.01 (2017), Sculpture,
[online] Available at: https://mimionuoha.com/classification01Trevor Paglen: On 'From Apple to Anomaly’, barbican, Anthony Downey, 2019,
[online] Available at: https://sites.barbican.org.uk/trevorpaglen/Understanding SSD MultiBox — Real-Time Object Detection In Deep Learning, Eddie Forson, 2017,
[online] Available at:
https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fabCode used in artifact by below examples
Data and Machine Learning for Artistic PracticeCode example: Week 9| Sound Classification
https://learn.gold.ac.uk/course/view.php?id=16040#section-12Code example: Week 3| Image classification demo
https://editor.p5js.org/joemcalister/sketches/nyGqF5SzRCode example: Week 3| Object detector via webcam
https://editor.p5js.org/joemcalister/sketches/eLHOmy1c8Code example: Week 3| Extra code example: pre-rendered video object detection
https://learn.gold.ac.uk/course/view.php?id=16040#section-12Code example: Week 4| Facial recognition on an image
https://editor.p5js.org/joemcalister/sketches/J9e-rO31sYCode example: Week 7| Style transfer
https://learn.gold.ac.uk/course/view.php?id=16040#section-12Neural- style
https://jkoushik.me/neural-style/Music used in sound Classification:
Great tit: https://www.youtube.com/watch?v=yEorCrgaVEU
https://www.youtube.com/watch?v=mkSNCdqU514
Blackbird: https://www.youtube.com/watch?v=Xc5LNhrH28w&t=57s
Sparrow: https://www.youtube.com/watch?v=y6Ccc2Povps&t=30s
Raven: https://www.youtube.com/watch?v=DDv_PlrBg14Pictures used in artefact:
Raven: https://pl.pinterest.com/pin/255368241345357665/
Blackbird: https://medium.com/agora24/my-first-and-oldest-friend-b97daecc078f
Sparrow: https://nl.pinterest.com/pin/394346511100949014/
Great tit:https://www.youtube.com/watch?v=mkSNCdqU514
https://www.weaselzippers.us/459003-great-tits-could-go-extinct-because-of-climate-change/Music used in the video: Moby- She Gives Me
https://mobygratis.com/license/rec73pBlTzvSg5375