




























































Audio-Visual Performance Tool
An audio-visual tool for a vocal performance that uses machine learning to 'sing' back to me in real-time.
produced by: Valeria Radchenko
Introduction
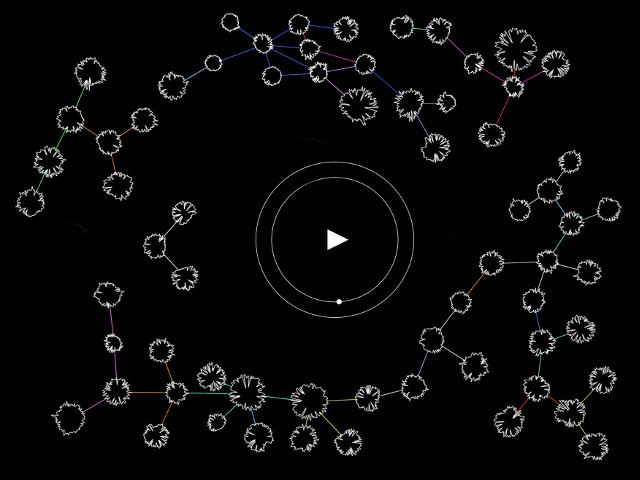
Openframeworks is used to analyse and visualise incoming sound. The peak frequency is sent to a Max patch through Wekinator using OSC, and controls the pitch of 2 sine waves and triggers vocal samples. As I sing into the microphone, my laptop responds in real-time.
The visuals consist of a grid of chromagrams using constant-q, the colour being mapped by peak frequency, and are used as a projection during performances. I wanted to keep it simple, just as a supplement to the sound, and to clearly show the relationship between sound and visuals. I tried several different options, such as stacking the chromagrams on top of each other, and played with having them rotate but the X shape worked best for projection.
Concept and background research
I’m interested in the relationship between humans and technology, especially in terms of creating art. The concept behind this work was to bring about a collaboration with my laptop, giving some control to the machine to explore call-and-response style musical communication, to highlight and discover what the machine can do. What happens in the margins of error, when my exact pitch isn’t found, or when it glitches? What is the creative potential of that which isn’t calculated or controlled by me?
I was inspired by Holly Herndon’s latest project, PROTO, a collaboration with an AI called Spawn. Her sentiment is basically that technology is still young and reflects what we put into it, so we need to choose what we’re feeding it and nurture it. My piece is still a very basic interface, as my fascination with AI is very recent (I didn’t take the machine learning module), but it serves its purpose - it responds to me in real time and alters what I do. Sometimes it harmonises, sometimes there’s dissonance.
I’m interested in the recursive feedback loop that occurs in multiple ways: the microphone picking up the output and responding to itself*, as well as my own response to the output (sometimes weki will estimate slightly off and I find myself moving towards that note instead). This aspect works particularly well as I work a lot with vocal improvisation, so having some kind of real-time input that also listens to me is great.
*this wasn’t captured in the documentation as I had issues with recording the audio, but I still found there to be a loop where the output (computer singing) influenced the input (my singing) which influenced the output and so on.
The Sound
The Wekinator model (neural network, 2 layers with 2 nodes) was trained with 15 pitches/frequencies with around 4 recordings for each. The peak frequency (input) is mapped to the pitch of several sine waves (output). In the patch (image at bottom of page) you can see 1 wave that outputs the input as is, 1 that subtracts 60 from the input and 1 that is multiplied by 1.25. 4 samples could be triggered if the input matched the argument (I used a range for some leeway). I also tried pitch shifting a vocal sample on loop, but found the sine waves to reflect the relationship between my singing and the output.
The sine waves act as a compliment to the voice, creating chords or acting as a vocal filter. At times the vocal samples are hard to set apart from my live singing but the visuals can act as a guide. I created this tool to fit into my practice which centres around using the voice and explores trance states through tech-rituals with vocal improvisation. That’s where the vocal samples and singing come in, but the sound of this differs from what I’ve done before.
Future development
· Explore producing specific scales, play with equations that would create interesting chords (in terms of the sine waves, in Max)
· Process the data somehow e.g. to delay the output, to do something different when I’m not singing (it tends to send lots of different numbers, so the output wobbles/dances)
· Turning it into a voice-activated sampler, triggering different components of a song/piece, eliminating the need to press buttons when performing. Maybe components of a song are triggered by sequences rather than pitch.
· Developing the ML side of it so it produces it’s own audio e.g. https://nsynthsuper.withgoogle.com/
Self evaluation
Wekinator couldn’t always find my precise pitch so the sine waves would sometimes stay on the same note despite me moving up or down a couple notes. In the case of this performance, it gave me something to play with, a way to explore dissonance. I also found the moments when I breathe and the sine waves start dancing erratically a bit distracting at times, it would be useful to find a way to control it so it could be done by choice. Overall I achieved what I set out to do and would like to work on this project further.
References
http://www.wekinator.org/examples/#Audio
OF inputs - “Various Audio Features”
MaxMsp outputs - “Simple Sine Control”
OF outputs - “simple colour change”
I modified the Various Audio Features example so it had just what I needed, and took inspiration from the Colour Changing output code to map my values to hue.
I modified the Sine Control example by adding and multiplying incoming values to create a chord of sorts with my voice. Certain frequencies also trigger samples.
PROTO by Holly Herndon
https://hollyherndon.bandcamp.com/album/proto