




























































Shelters
An experimental fashion film project using interactive video visual processing built with computer vision techniques during the filming process to explore a new way of fashion presentation/performance, which transforms the camera from a documenting recorder to a live narrative editor.
produced by: Bingxin Feng
1. The edited version (Haven't officially released yet)
2. The Livestream version of the 2 hours filming
Introduction
Shelters is an experimental fashion presentation with an ambiguous nature in between a film and a performance. It presents 6 looks from the textile designer Jojo Yue Zhou’s diploma collection. And there are 4 categories of narratives (interactive video processing design) for every look.
There are 2 presenting forms for the project Shelter. One is an online live stream, which presents the complete process of this fashion presentation, including makeup, styling, the actual performing, and some referenced/inspired visual elements from the designer’s collection research - This online live stream is a hybridization between performance and documentation. And the other form is an after-edited film, edited with the recorded footages of the interactive performance process.
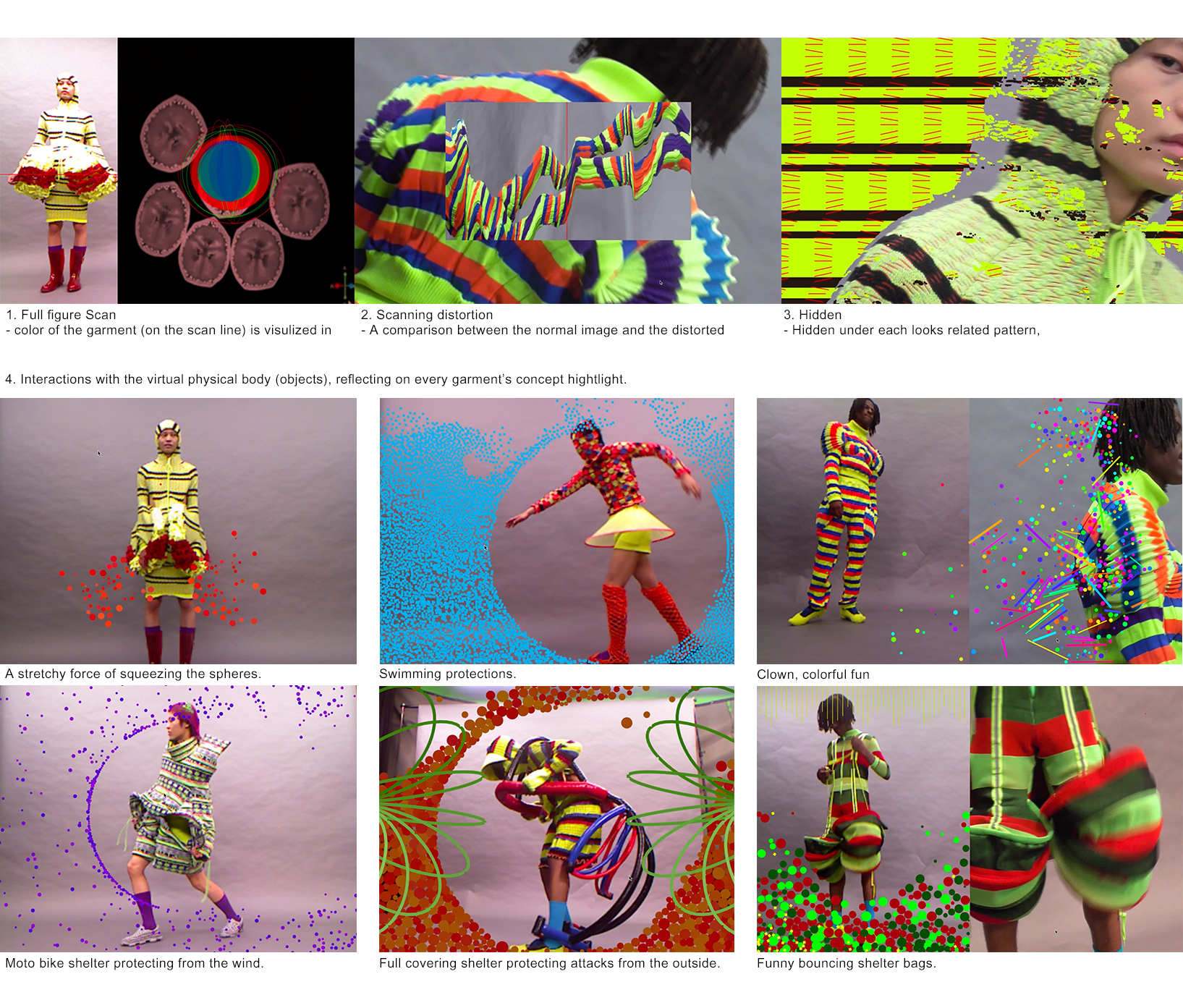
Concept and background research
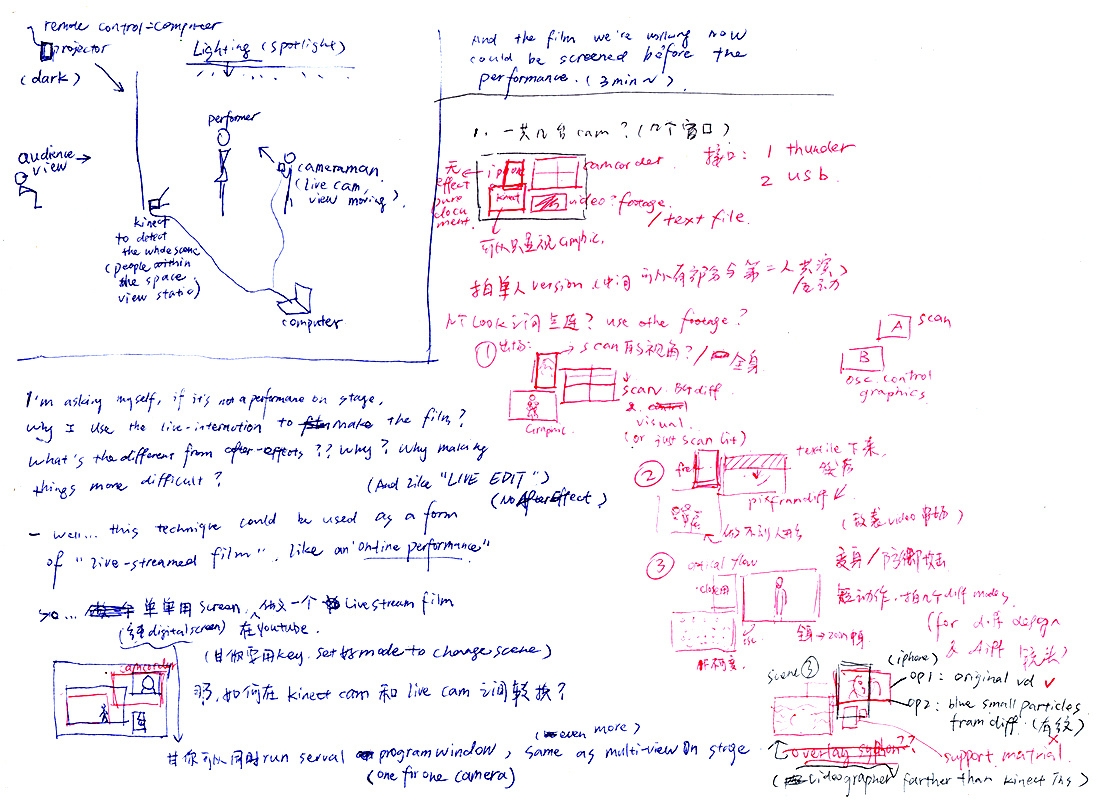
For this project, my initial idea was to make a performance in the real world - a performance using live camera filming projection on the stage. (Initial project proposal here.) Because I’ve been attracted by performance like Tesseract by Charles Atlas, Rashaun Mitchell and Silas Riener, and Not a Moment Too Soon by Ferran Carvajal. In those performance, the camera / the projection screen becomes an additional dimension on the stage. Because of the different viewing angles of the videographer, and the various live interactive video processing, the audience not only see the performers and the stage from their own eyes, but also from the camera’s eye, from the computer’s eye. This multi-dimensional watching blends different time and space together, offers the audience a more complete, more conscious spectatorship. And for the performers, they are not only acting by themselves, they are also reacting with the video projection on the stage. For them, the live feed video projection is their another self on the stage, is the other world they experiencing on the stage, so there is a collaborative relationship between the videos and the performers, how the performers act affects what appears on the video, and same in the other way around. And I also think it works the same for the cameraman filming that feed. So in this case, the whole scene is created collaboratively by the performer, the cameraman, and the video feed.



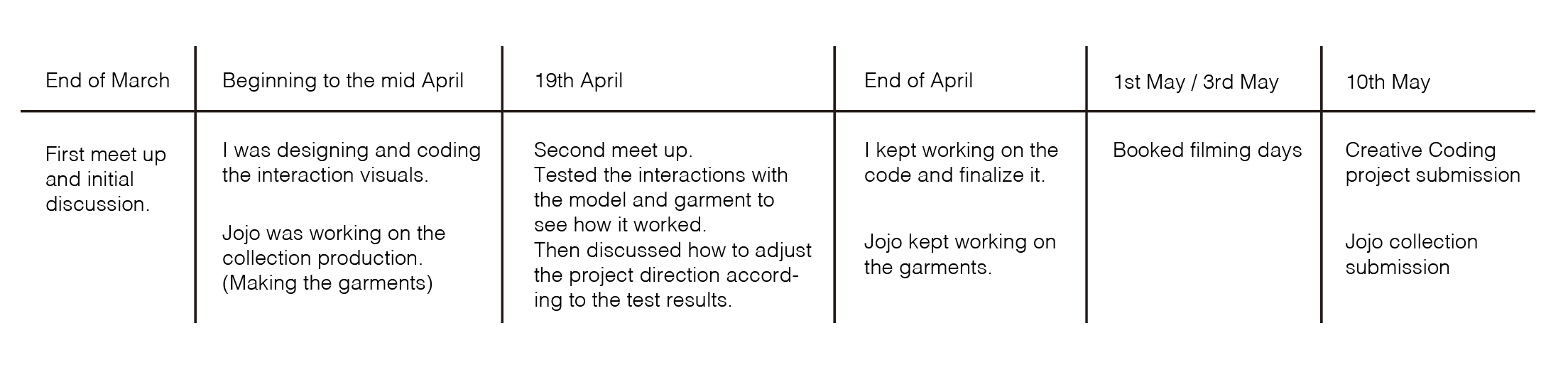
- Working process
I was ambitious to experience and explore this hybrid creative process, so I asked my friend, the textile designer, to collaborate with me to make a performance presenting her collection in this project. And our workflow was like this:
Our initial plan was to let the models wear the garments and do some movements/behaviors as the performance, and use the half-transparent mesh projection in the performance, and we planned to film the performance in the studio, and use that as the fashion film for the collection. However, after I started working on the interaction design and codes, I realized that modeling is actually very different from dancing as a performance, the strategies work for dance performance actually doesn’t work for the modeling. My reference projects are all dance performance, and the key point of working with interactive visuals like the one using frame differencing / background differencing is the Movements. But when I actually tested with the model with the garments, I found that there’s actually not much (dramatic) movements in the modeling……(Of course the model can move dramatically, but it didn’t work well to present the details of the garments.) Also if I used the projection mesh, firstly the environment needs to be a dark space with a very specific spotlight behind the mesh, secondly when modeling behind the mesh, both the projection on mesh and the model behind were not showing to the audience clear enough. And we won’t have enough time to solve these problems. So basically we found that it would be a mess and in no way satisfying the demands of showing the garments if we insisted to make it as a performance. Therefore, I decided to give up the idea of using the projection. And instead, in the later experiments, I found that using the windows in the screen (monitor) could build the multi-views scene as well, not on the stage, but in the virtual space. And that’s why I came up with the idea of the live stream - an on-line multiple views live performance.
However, in the end, in the actual filming, because there was only one cameraman (me) and I had to take care of the program on the computer (running smoothly or not crashing), it was impossible to do the filming from multiple cameras at the same time. Also because the designer (Jojo) wanted an edited version of the film, considering that the resolution of the footages recorded from multiple small windows in one screen might be too low, in the end, we ran one view one big window once on the screen in the actual filming.
Making Process Documentation Video:
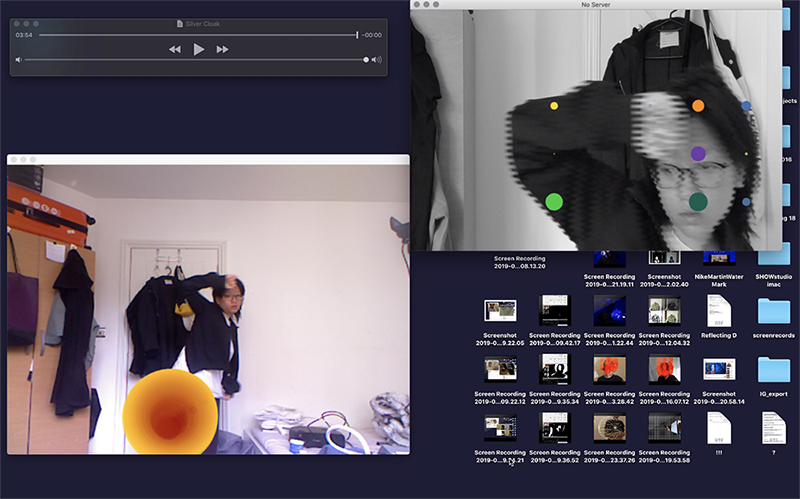
sketches and experiments screenshots:
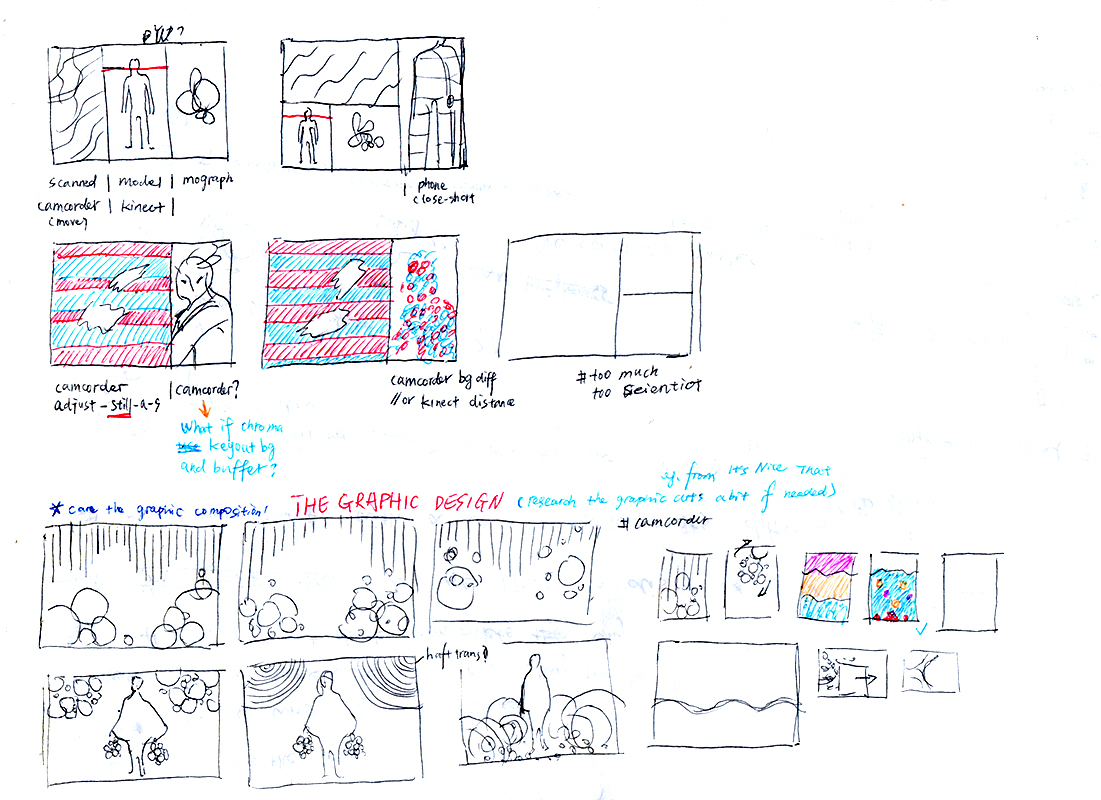
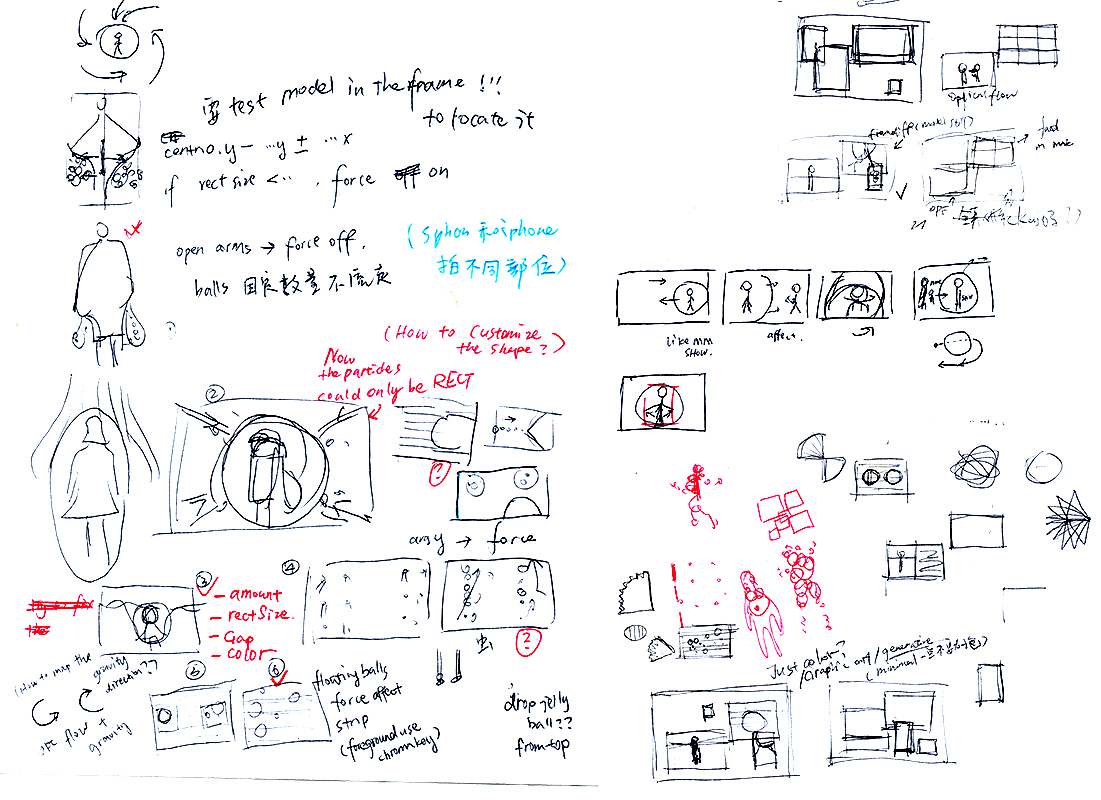






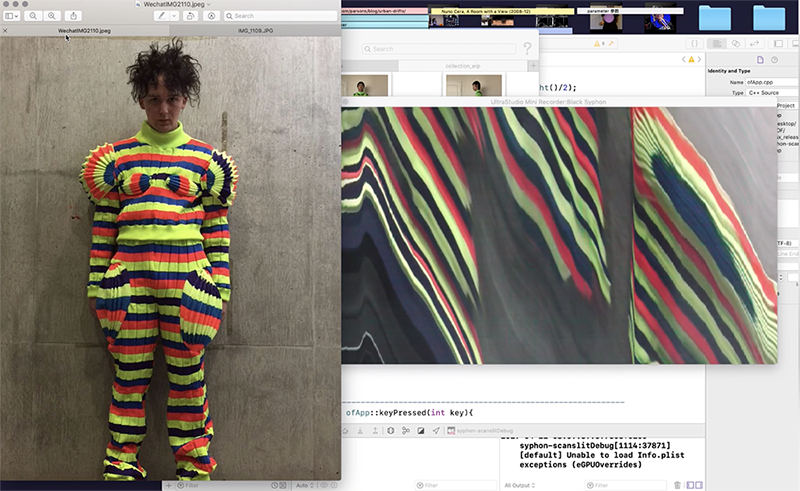

Technical
This project was built with OpenFrameworks. The first big challenge for me was to bring the camcorder live feed into OpenFrameworks. (Because I can’t do proper filming with a webcam.) I researched the questions in the OpenFrameworks and GitHub forums and found useful information that I could either try the Blackmagic Design Ultra Studio Mini Recorder and ofxBlackMagic, or try the ofxCanon. In the beginning, I bought the mini recorder and the wires, the adapter I needed, and run the example program of ofxBlackMagic, but it failed to compile…… I asked a few questions on GitHub, but didn’t get any response so far. So I turned to try ofxCanon. However, although I’ve applied and got the Canon license for the developer, it didn’t work out in the end. (I think it’s because I didn’t get the Canon app for livestream?) Then when I almost gave up, I found that there’s an addon to transfer data between other software and OpenFrameworks - ofxSyphon. And it works with the BlackMagic products with the software BlackSyphon, which transfers data from BlackMagic to Syphon, and ofxSyphon transfers data into OpenFrameworks. With these tools, I could use a live feed from the camcorder in OpenFrameworks.
In the ‘Full figure scan’ part, I calculated the average color (in RGB) at where the scan line passed, and use those RGB data to affect the color tone of the MRI scan video, the shape size and the rotation degree of the RGB sphere. And I found the way to calculate the average color from this post in openLab.
In the ‘Scan distortion’ part, I used drawSubsection( ) with a sin parameter in it to have the dynamic scan distortion.
In the ‘Hidden’ part, I used frame differencing, copying the pixels colors from the camera feed image, and draw the pixels at where the frame difference occurred. And I noticed that in the lab examples, to reduce the CPU tasks, we don’t draw the shapes on every differenced pixel, but draw them on 60~70% (even less) of the pixels. But when I’m drawing the camera feed on the differenced frames, 60~70% would not be enough to draw the complete video feed (it would be too sparse), 100% would slow down the program extremely, so 85~90% was a better result.
In the ‘virtual physical body/object interaction’ parts, I used the addon ofxLiquidFun as the main visual elements and created the interactions with openCV centriole locating and/or optical flow. OfxLiquidFun is a modified version of ofxBox2d. It’s an amazing tool to create virtual worlds with physical force/gravity. Through learning with the example projects, I created the liquid-like particles, wind-like particles, stretchy forced balls, and bouncing balls pool, etc. in this project. And through looking in the ofxOpenCV, I got more practical with the OpenCV contour finder, bounding rects, and centriole, etc. which are very useful to locate the object position (and size) in the Kinect.
Future development
This is the very first time of a lot of things for me in this project. The first interaction project with fashion designer, the first filmmaking with interaction, the first live filming with coding, the first mixture of film and performance, the first attempt using coding for performance……I am aware that there’re too many things I tried to do in once in this project. The lack of experience and related knowledge, with curiosity and ambitions, became such a poison in the project. But that also means that there's a lot more development I could do for this project.
I would like to try using the half-transparent mesh projection when I have more time. And do more experiments on the visuals of the video processing - according to a more careful consideration of the relationship between the visual and the storytelling concept. Because this time I spent too much time on the technical problem solving, also because in the concept (story narrative) building stage, the garments were not finished producing, the project time management was quite tricky (as we both had tight deadline), it’s difficult to really think about the narrative concept before actually knowing how the garments look like. And the absence of storytelling kind of failed the performance/film. So for further development, I would definitely work more on the basic narrative concept.
Also, the online live stream performance/presentation idea is very appealing to me. I would definitely try it with the multi-camera feed, and with more other kinds of source like other images, audios, music, even designer interview, etc. Like the project ‘Honey I’m data’ from HerVision. And according to the experience from this project, now I know that one of the challenges for the development would be how to switch the different scenes smoothly, showing less unnecessary/non-performance scenes like looking for files, opening files, etc.
Self evaluation
- About live and real
I’ve been thinking during this project that why I so insisted of the live camera feed - if my purpose was to make a video using computer vision interactive techniques, why don’t I just do the filming properly first, then process the video with the code later? Then from my obsession of the related works (like Charles Atlas’s Tesseract) and the practical experience in this project, I think the answer is about the liveness and realness. I’ve been always wanting to do works lays between the physical and the digital, or rather saying, the virtual and the real. Like conventional after-edited moving images, which are fascinating, yet usually, be considered as fake (which makes it less fascinating and somehow less profound). While the live videos, or live generated images, could be considered as real - which is happening right now, right here. And the experience of liveness is more engaging and more conscious. Like in this project, although I didn’t make the livestream public to the audience live (because at that time Jojo’s collection was not allowed to be exposed to the public), but during the filming, me as the cameraman, I definitely perceived how the live video possessing (the live generated/affected visual) affected my feeling, affected my direction of the camera manipulation (i.e. my view of narrative at that time). And for the model doing the performance in front of the camera, they were not just acting with empty air, since they were told what they were interacted with, and they could see the live video processing from a big monitor in the studio during the filming, they were engaged with the live video processing, their actions and the live videos affected each other in both-way. And I saw these moments as when the virtual and the real world interlaced together. And that’s the idea I’m going to explore further.
- About aesthetics and experience
The other thing I struggled with a lot in this project was about the aesthetics and the experience. During the making of this project, I kept having a negative feeling for what I created. Because I was standing in a filmmaker/ art director’s shoes to see this project - I was not satisfied with the visuals I created from the interaction in OpenFrameworks. I could not stop thinking that comparing with the visual elements I would / could create in Adobe AfterEffect/ Premiere Pro, the visuals I created in OpenFrameworks just had such a bad aesthetics and low efficiency to visually communicate. (Also because of the pressure from the designer, obviously what I created in this project is such a difference from the conventional fashion films I created for her previously. So we were both a bit lot during this project.) Then in the later stage of this project, I talked about this issue with other peers in our course, and did a bit more research about interaction and video art. From my dear peers' feedbacks, and inspirations from video artist like Peter Campus and Charles Atlas, Rafael Lozanno-Hemmer, and Mattias Oostrik, etc. I realized that the interactive video and the conventional video I worked with before are completely two different things. In interactive video, people don’t make sense of the video from its aesthetics, but from their embodied interactive experience with the video. It’s not about how aesthetically nice it looks, but about the experience, about the way how people 'inter-act' with the video, and then what people perceive from such interlaced relationship between themselves and what appears on the video.
Considering the project outcome and the project making process, I was not very satisfied. But considering that after such struggles and pains, in the end, I realized the essential nature of the interactive video, and figured out where to go in the further experiments - not a bad experience! Since the medium is always video, I reckon it’s not that easy to transform the way of thinking from a filmmaker’s view to an interactive video artist’s view. I’m happy that I learned it through this project, and I can’t wait to explore my ideas in further development, as an interactive video artist/ computational artist.
References
1. ofxLiquidFun addon from Github-tado https://github.com/tado/ofxLiquidFun
2. Solution of using fbo to convert Syphon to image: https://forum.openframeworks.cc/t/ofxsyphon-to-image/7791/4
3. Solution of the live camcorder in openFrameworks: https://forum.openframeworks.cc/t/what-is-the-best-device-to-capture-an-hdmi-video-stream/24333
4. ofxSyphon addon from Github-Astellato https://github.com/astellato/ofxSyphon
5. Solution of locating CV blob: https://forum.openframeworks.cc/t/finding-center-of-opencv-blobs/11836