




























































Rrosetta
Rrosetta crafts bespoke self-published zines using sensitive personal data.
by: Howard Melnyczuk
Rrosetta is a data-driven application that seeks to analyse sensitive personal information to create a unique and cherishable publication. Coming out of the niche and often intimate subculture of zine-making and self-publishing, Rrosetta also offers a way for me as an artist and publisher to critically explore wider cultural narratives arising out of the proliferation of the tech industry. On setting out on this project, it was crucial that I pay close attention to any questions arising from the intersection between two distinct fields of concern: the strengths and shortcomings of technological approaches to autonomy, craft and agency, and a focus on the price, cost and value of art and data.

I was intrigued by the ways in which machine learning & data analysis models can or cannot function as a poetic substitution for human agency. Beyond this, I also wanted to use this project as an opportunity to explore how big organisations (such as Google) shape the way in which masses of varied people use technology, constraining and shaping how users organise themselves, their (often private) correspondences and their personal lives.
The computation of personal data tends to focus more on the “data” than the “personal”. This mixture of personal and big data brings out two ideas of agency: human and data-driven. Data-driven agency seeks to present correlations between the behaviours of various users without understanding any single individual. These correlations are often argued to surpass the necessity of knowing the individual (presenting the raw objective behaviour patterns), but they also present deterministic categories that lack nuance. In categorizing users by their data, institutions are able to exert power and influence over their users’ behaviour.
Given these concerns, it was imperative to me that the artwork itself provoke and problematise these types of power structures. This blend of the personal and the political led me to the use of zines - an intimate, often hand-crafted and relational medium. Zines are so often as much an activity for their author as they are for their reader. They are made with love and read with love. What crafts this fondness and could a computer create something equally affecting?

How much do we value our own data? How threatened do we feel by automated systems, and how much are we willing to trust them? Given a conscious choice, how do we evaluate the relative risk/reward of non-monetary, non-traditional economic situations? Does the invoked agency of an inanimate system increase or decrease our apprehensions? Rrosetta was, for me, a way to pose these sorts of questions as eloquently as possible.
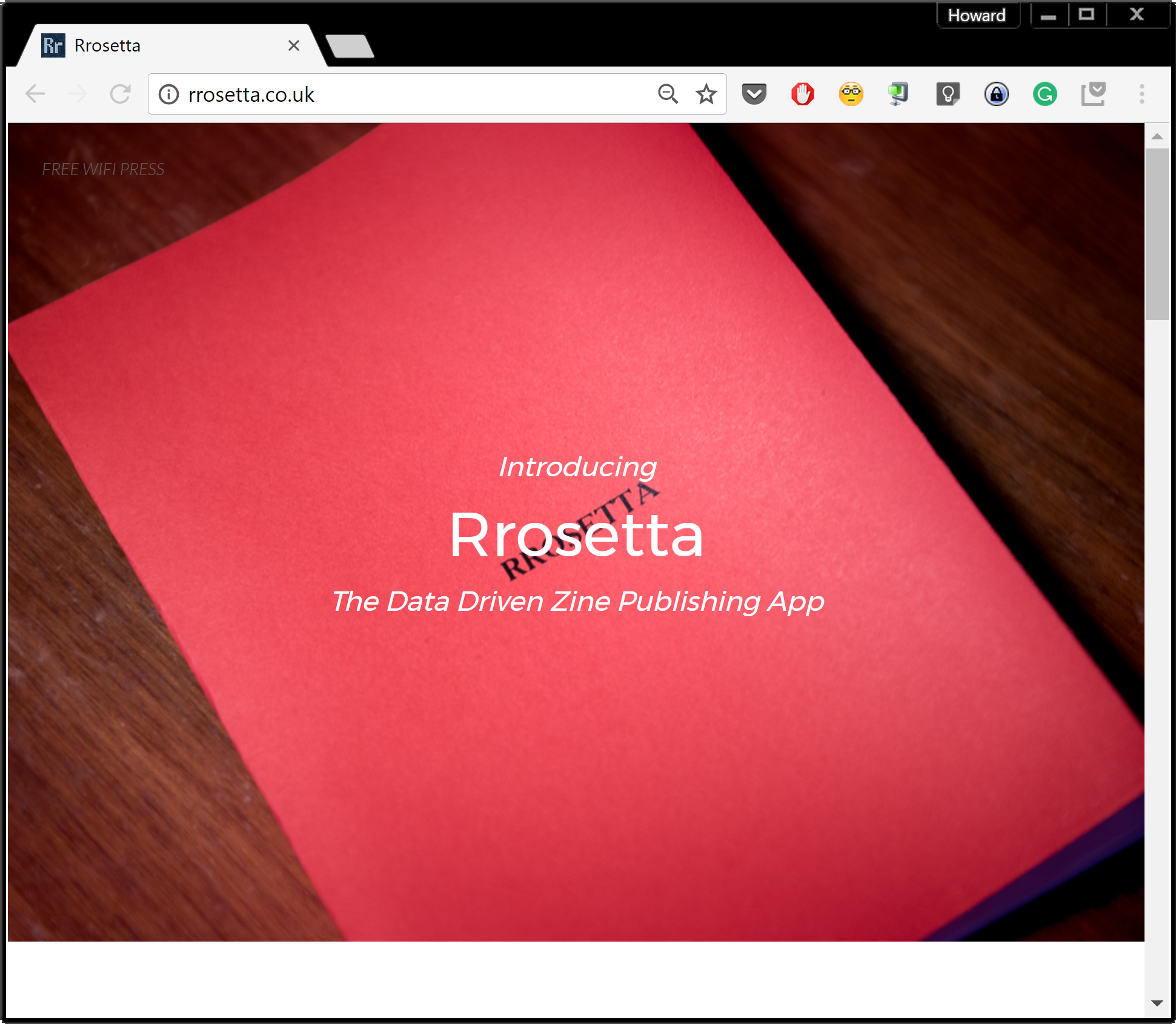
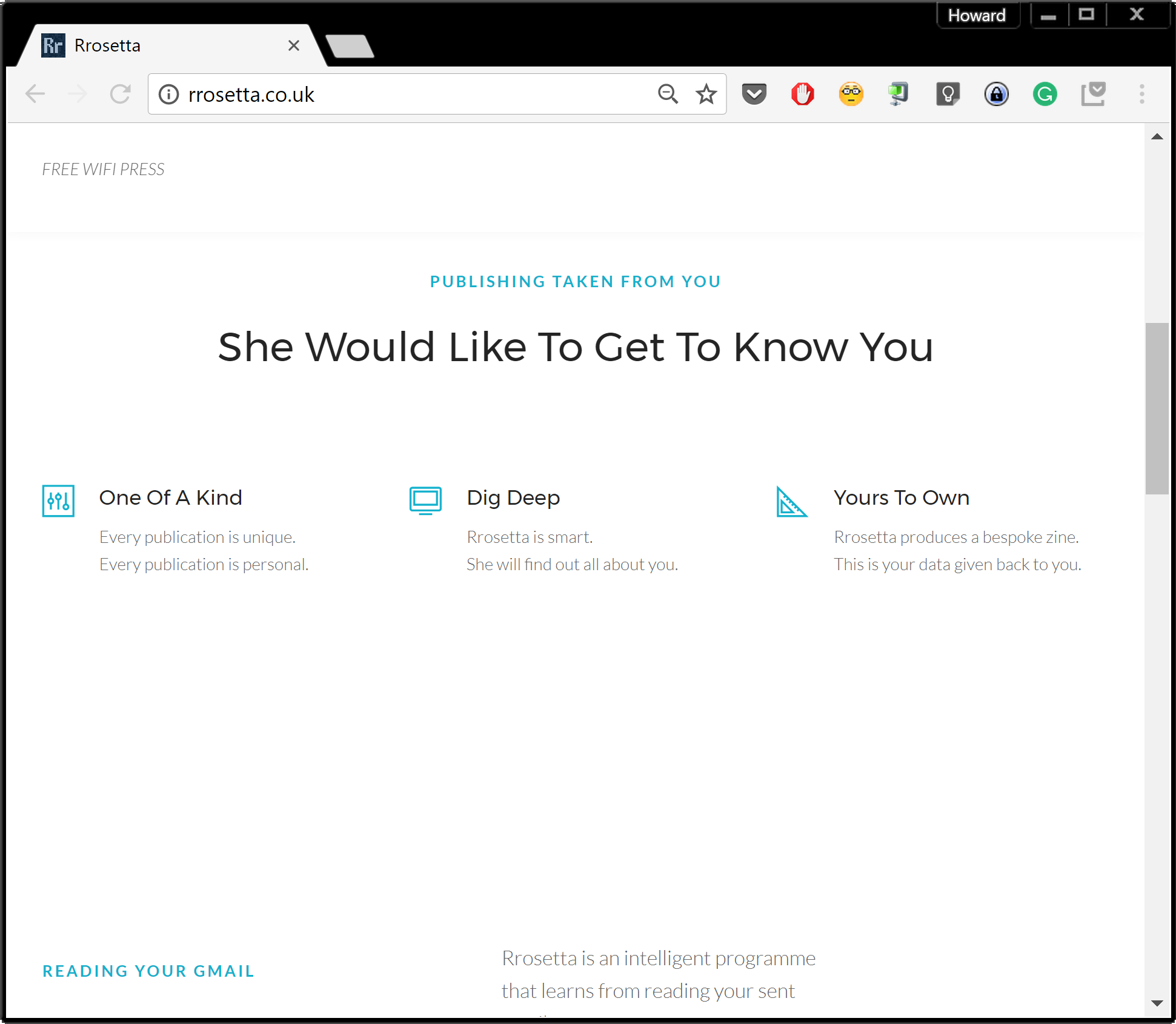
Screenshots from www.rrosetta.co.uk
When exhibiting Rrosetta, it was important to frame the piece correctly in order to convey the themes and provoke the intended questions. The piece is largely conceptual. I wanted to couch it in the familiar aesthetics of petit bourgeois tech industry; what Kyle Chayka has called the “globalized sameness-as-a-service” of Silicon Valley coffee shops that are now present worldwide. This aesthetic is both disarming and uncanny. This is precisely where I wanted Rrosetta to fall. To heighten this atmosphere, I accompanied the scene with a bookshelf stocked with carefully selected titles from dystopian science-fiction to critical and art theory. Not only do these provide reading material for the user while they wait for their zine to print, they also bring the audience into the same cultural space that Rrosetta inhabits. They remind us both of the intelligence and beauty of human endeavour, and the darker sides of human nature.
The title of the piece and programme was also carefully chosen to emphasise these themes. In “On Software”, American critical theorist Wendy Chun discusses the gendering of automation: something that has come to the fore with the release of intelligent assistant systems such as Amazon’s “Alexa” and Apple’s “Siri”. It was important that the programme have a female persona, calling into question our assumptions about passivity and servitude in terms of both gender and technology. The introduction of the second “r” into the generic female name “Rosetta” is inspired by “Rrose Selavy”, a female alter ego taken on by the Marcel Duchamp. It also gives the unnerving notion of being an erroneous typo.
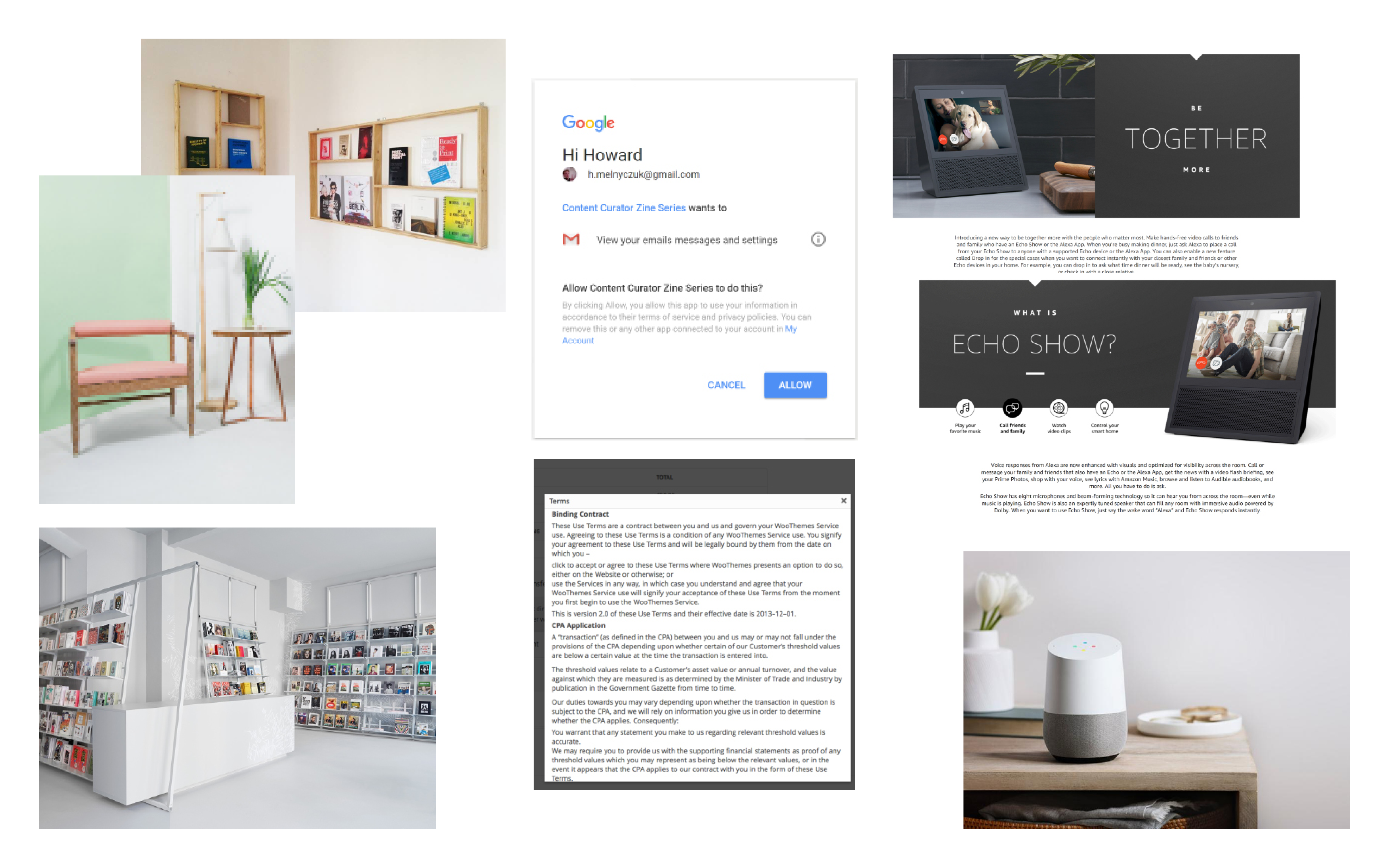
Early moodboard containing the blend of coporate aesthetics I wanted to critique.
In “Towards a Philosophy of Photography”, the Czech theorist Vilem Flusser argues that the ontological logic of cameras is to take every possible photograph, driving us in a frenzy of snapshots and angles. This notion has had a great influence on me and my practice, given its parallels to the distribution of photography on the internet. This is what led me to my interest in web-scraping.
Upon starting the project, I had next to no knowledge of Python. I had however used it to do a simple web-scraping exercise, and had heard it was excellent for quick development. I had also read that its development had been heavily funded and supported by Google, in the late nineties and 2000s in order to facilitate their ambitions with machine learning and data processing. Beginning with a few quick scripts to scrape text and images, I found Python not only incredibly useable but also very adaptable to what I was endeavouring to do, given its extensive modules for data analysis, machine learning and natural language processing. There was also extensive documentation by Google regarding their Gmail API in Python.
I felt it was crucial that I use the official Google Gmail API and the Google OAuth2 authentication protocol, both for the security and legitimacy of my project (working as I was with sensitive user data), and also thematically by making Google an inadvertent but nonetheless complicit collaborator in my project. I began by reading their terms of service to check what I was planning to do was permitted.
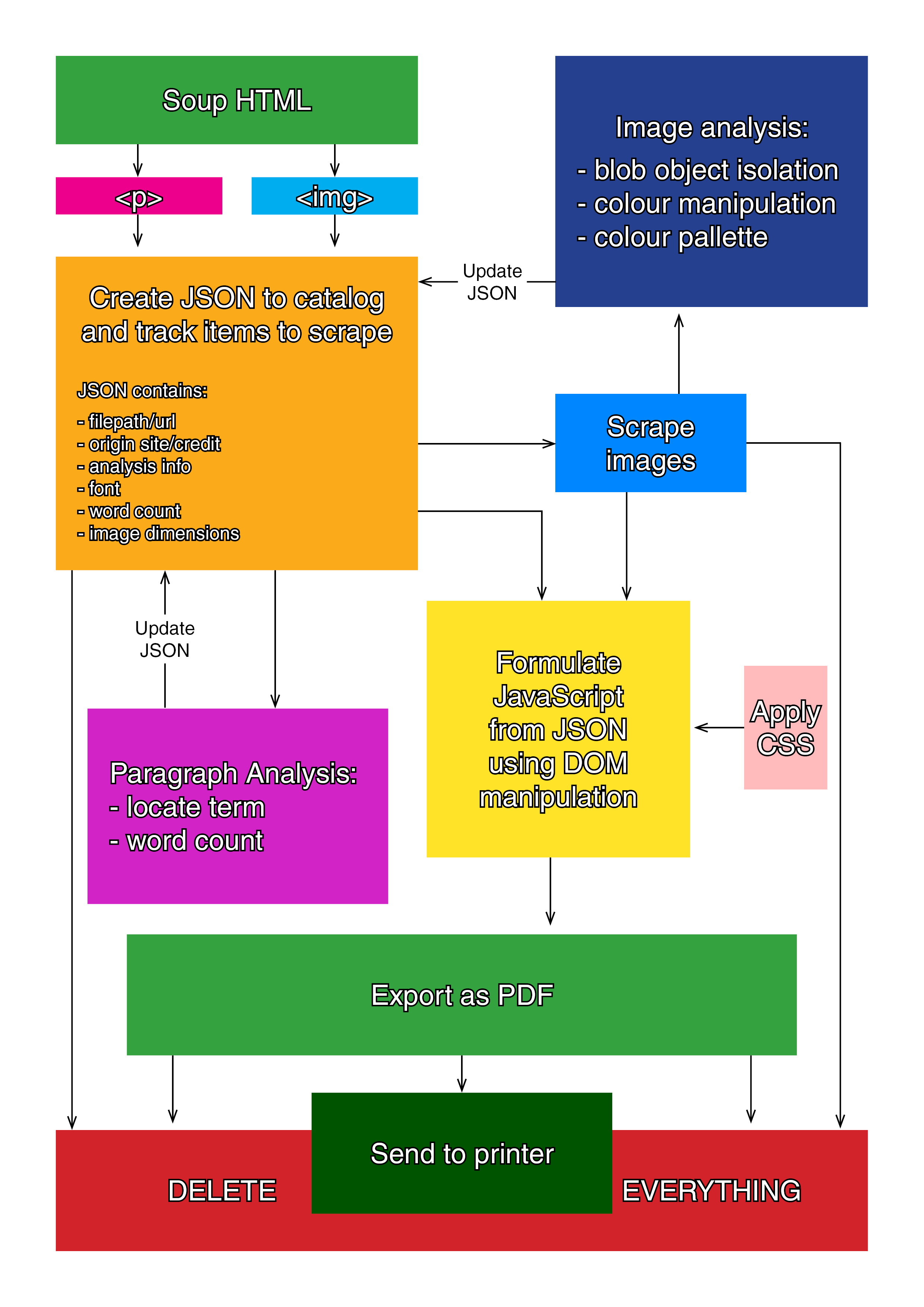
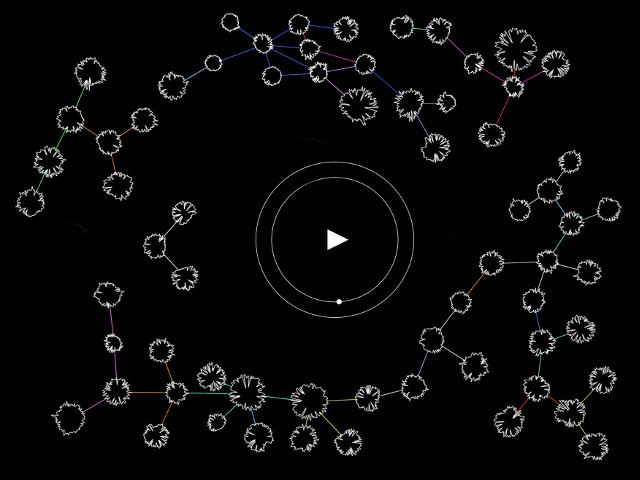
Diagram outlining the plan of my algorithm.
In addition to the Gmail API, my project relies on a number of Python technologies:
- Sumy, a text summarization module. This returns sentences from a body of text that are exemplary of the text as a whole. It uses a number of machine learning models, mostly trained on news articles and headlines. Sumy allows for multiple sentences to be returned, so I implemented a recursive method that feeds the sentences back into Sumy to improve accuracy. This pulls 2048 sentences from the entirety of the user’s emails then repeatedly halves and summarises these until only 4 are left.
- Py Web Search (PWS) which performs a Google search using each sentence. When I first implemented PWS, it suffered a fatal bug that made it all but unusable. To get around this, I had to create my own patch from the PWS source code. With this, I am able to return the top ten links for each Google search.
- Beautiful Soup which scrapes and parses the HTML from each site returned from the Google searches. Each paragraph and image tag is stored in a dictionary. Some basic analysis is performed to discover if the text contains any useful features (such as blockquotes) and to find the dimensions and filetype of all the images.
- Reportlab to formulate the zine and save it as a PDF. Once the PDF is saved, the programme sends it to the connected printer.
- Django, a Python server framework. Initially this raised a number of OAuth2 issues, which I was able to resolve with the kind help and guidance of Fabio Natali. I then tried to host the Django server online via Heroku, but found this did not allow me to easily save and print the PDF files.
In the end I decided to run the Django server on a local host, then tunnel into that using a service called Ngrok. In doing so, I triggered Google’s automated safety check that warned users that Rrosetta was insecure. This was, thematically, an added bonus, reducing the ‘frictionless’ nature of the app, and giving the user more time to pause for thought.




Images tweeted by @matt_mjlc
Rrosetta is being exhibited again in a few weeks, which has given me a great motivation to find ways to improve it. Firstly, I would like to make it operate more robustly by moving it from a local to web-server. I hope this may make it easier to handle the flood of requests to use the service, as this made the server slow and sometimes crash. I also want to implement an automated email messaging response to inform users of the status of their zine. By developing the project in this way, I hope to learn more about backend web technologies. I hope this will facilitate more investigation into how databases function, so that I can reincorporate this into my critical practice.
Once the project is no longer being shown in galleries, I may turn it into a web app that allows you to print your own zines at home. This could come with extra functionality, but I fear it will lose much of the conceptual strength of the exhibited Rrosetta.
The project followed a steep learning curve and there are many areas I would like to spend more time learning about and working with. Having now developed a confident understanding of Python, I would like to do a number of projects using Scikit-Learn and Keras: machine learning modules that I would have liked to use to make Rrosetta smarter.

I spent a long time learning about and implementing Python’s Natural Language Toolkit (NLTK) in order to find ‘interesting’ nouns that users often talked positively about. After building a sentiment analysis script, running it on my own emails returned the word ‘thanks’, which, whilst satisfying the criteria, was largely useless. This was however very useful as it taught me a lot about automated text formatting and analysis, using Regular Expressions and other concepts that were essential to my project.
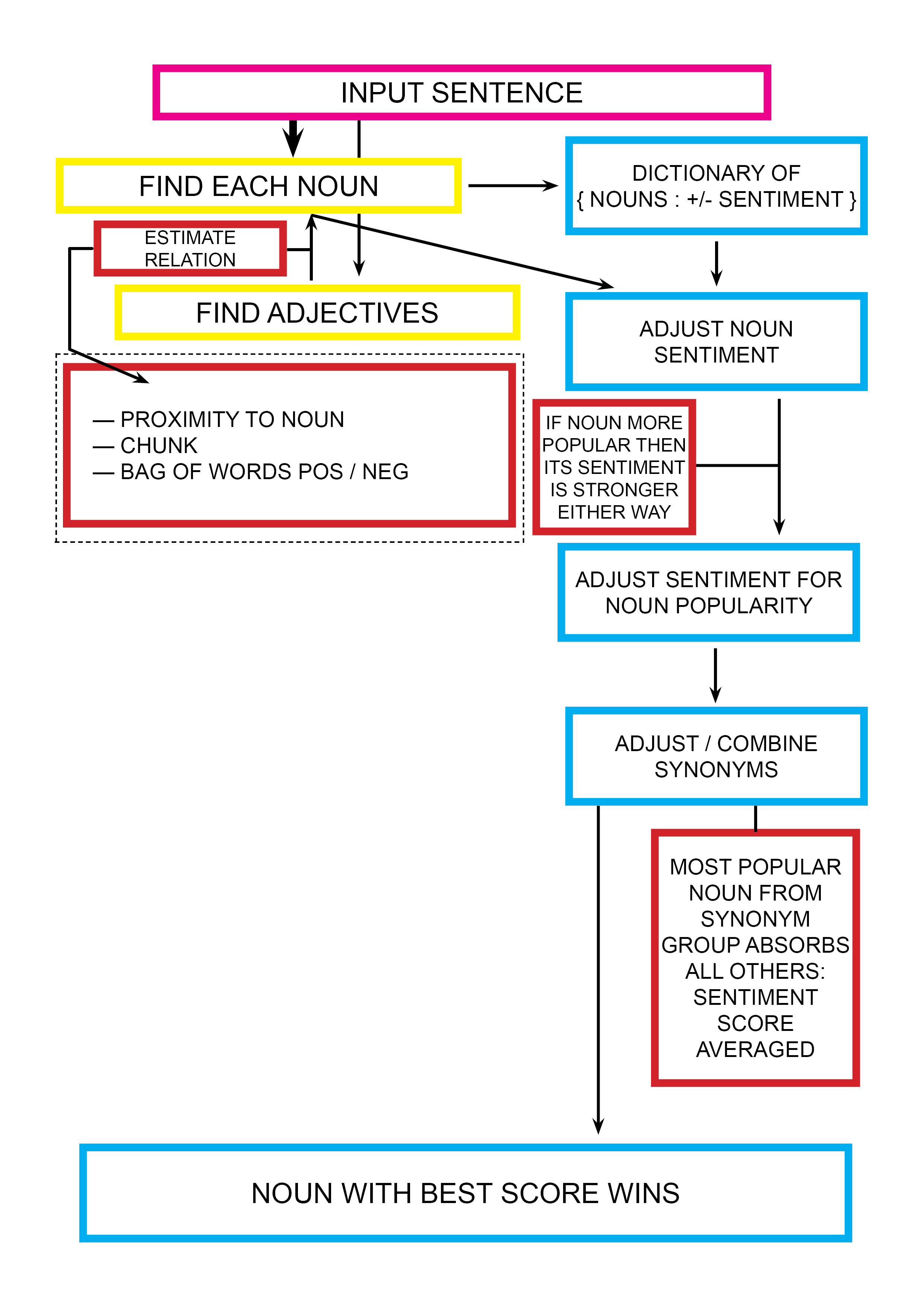
Diagram for NLTK based sentiment analysis algorithm.
I feel that this project has been a firm first step toward developing my publishing practice to incorporate computational technologies. I would like to do more research into forms of computational photography, and computational design - especially for print media. Whilst I was happy with the aesthetic of the zines Rrosetta printed, the arrangement algorithms I used are far from a computationally ‘sophisticated’ approach. I would like to devise a way to analyse each design element so the form has a stronger relationship to the content, but this is a vast project all by itself.
I was extremely happy with the responses I received during the exhibition. It would seem that, despite the largely conceptual nature of the work that the audience understood what I was critiquing, and enjoyed both the experience and the outcome despite of its somewhat demanding formulation. It was very interesting to see so many differing responses, from horror to joy and I so I feel the project was very successful.




References
- Welcome to Airspace -- Kyle Chayka (link)
- On Software, or the Persistence of Visual Knowledge -- Wendy Chun (link)
- Towards A Philosophy Of Photography -- Vilem Flusser (link)
- Meet Rrose Sélavy: Marcel Duchamp’s Female Alter Ego -- Alexander Hawkins (link)
- Sumy -- Python module (link)
- Py Web Search -- Python Module (link)
- Beautiful Soup -- Python Module (link)
- Reportlab -- Python Module (link)
- Django -- Python server framework (link)
- Natural Language Toolkit -- Python Module (link)
- Scikit Learn -- Python Module (link)
- Keras -- Python Module (link)