




























































Wordlaces
Circular poetic word paths using the Levenshtein distance
Jérémie Wenger
March
2018


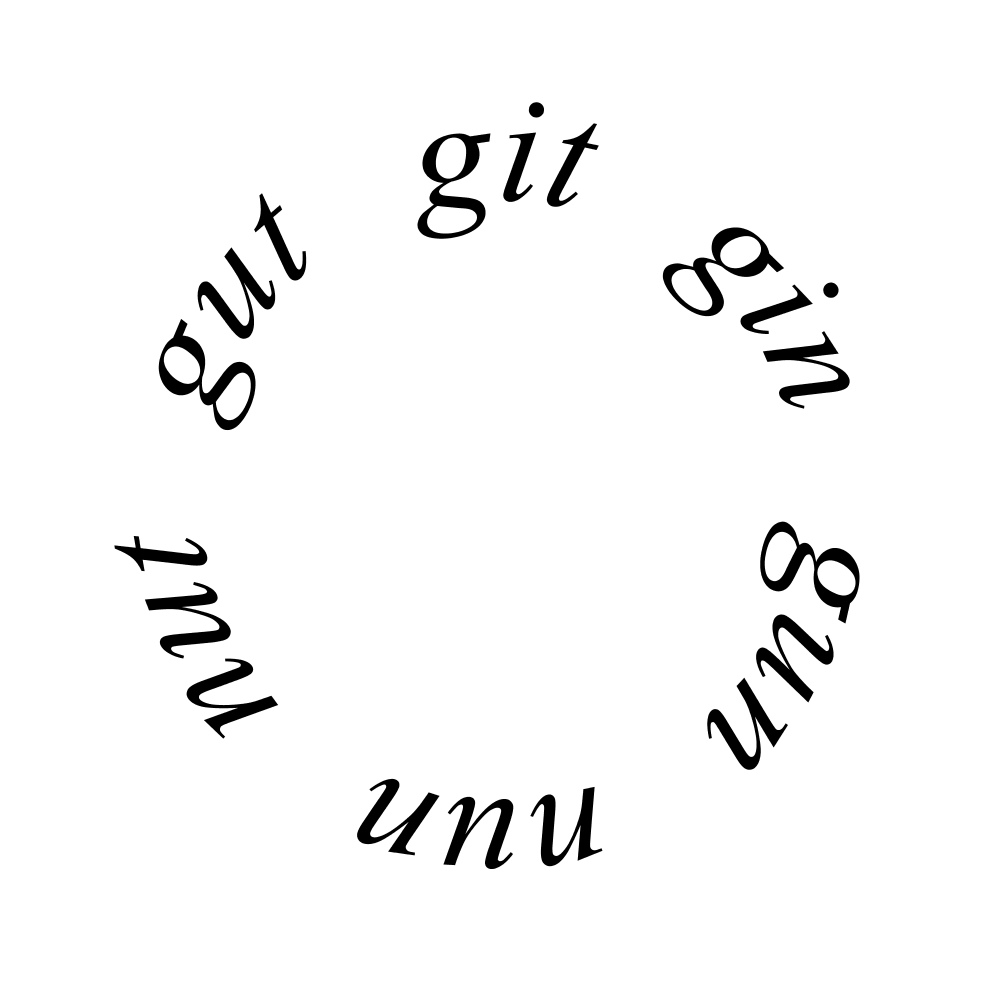






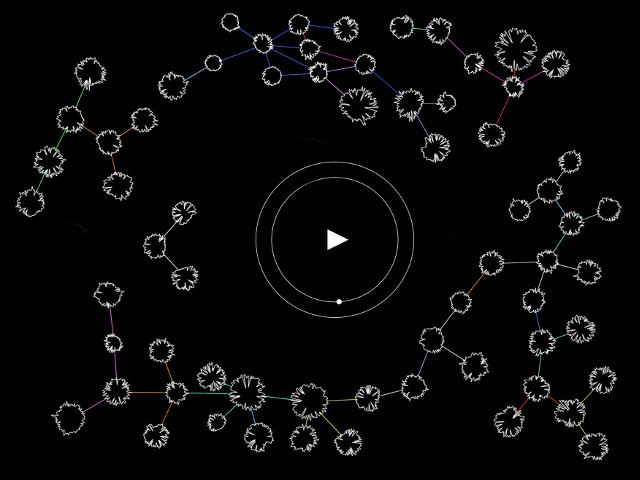
Wordlaces are a highly constrained literary form based on the Levenshtein distance, a type of edit distance. From one initial word or 'urword' and a given dictionary, in this case a list of words of the same length, one finds all the words that have only one character differing from urword's (yielding a Levenshtein distance of 1). From this first generation, one chooses one word and repeats the operation while making sure always to increase by one the distance from the urword at each iteration. This algorithm allows us to reach an 'alien word', one with no character in common with the urword, as fast as possible. Once this is achieved, the same method is applied to find a path back to the origin. No word repetition is allowed throughout the lace.
This paper offers insights into the techniques used and developed to experiment with this literary form. The initial technical impulse for this research was the discovery of Natural Language Processing (NLP), the field of computer science devoted to natural languages, and in particular the Natural Language Toolkit (NLTK) library in Python. After that, the actual wordlaces are described in more detail, while the final part is focussed on the implications for literary practice of the use of constraints, the systematic generation of result copora, and the intermingling of literary writing with data mining.
The full text in Markdown and pdf, the code and examples are available in this repository, whilst a blog retracing my thought process during these two terms can be found here.