





























































produced by: Valerio Viperino
This project is the result of realising that what I had a week before the final deadline was not good enough and I needed to completely rethink and rebuild it in less than a week.
My original idea was a simple motivator machine which - after the press of a button - would generate and display different kinds of motivational sentences, from the most nerdy ones (“May the Force be with you”) to an “interesting” blend of fortune cookies and classic motivational quotes achieved thanks to custom trained Markov Chain.
Unfortunately, I came to spend too much time before having a first MVP of the machine due to a huge number of technical issues, and when I finally saw it at work it really didn’t resonate with me.
So I dropped the original idea and I got inspired from my computational art research. I was working with data visualisation and studying different approaches of representing data while one night I came with the idea of “sonifying” the huge amount of tweets that constantly flood the internet.
“What if we could literally hear those thousands of uninterrupted people talking?”
Then #TwitterHead was born.
Given the experience gained from developing a too convoluted idea (the motivator was making use of an e-paper display, i2c communication with Arduino and Raspberry Pi and a lot of buggy software) this time I had to work simple and quick.
I was able to get a rough working software prototype written in nodejs using my Mac machine in just one afternoon (thanks world of the open source!).
I then started working on the hardware side. I created the 3d printed envelope using fusion360 and I started to try to use a raspberry pi zero as the main board on which to run the Text To Speech app, but it was too slow to provide a good development workflow so I realised I had to move to my udoox86 board.
Top and bottom of the 3d printed envelope:
This greatly helped me because I also didn’t need anymore to use a PiHAT to output the audio, instead I just had to amplify the line level signal coming out of the stereo jack of the udoo. This was achieved using a stereo amplifier bought from my local Maplin (after initially blowing up a much cooler one from Adafruit.. things that happen if you’re working at night).
I then started debugging the app using my udoo ubuntu board, only to find out that the beautiful synthesised voices that I have installed by default on my Mac are obviously missing in any other OS.
So I installed festival, an open source alternative, and some of the best additional voices available which were sounding so terribly robotic and unnatural.
Just the night before the project presentation, while I was struggling in search of a better alternative, I came across Amazon Polly, which is an AWS service that synthesises voices on the amazon cloud platform and gives you back the result.
Then, for the second time in my life I had to thank Amazon (first time being when I bought the Prime).
Even if they collect god only knows how much data about me, they at least give you the chance to use Polly for free if you’re below certain usage thresholds.
Future developments:
I would love to build a body for my TwitterHead and create a full human sculpture underneath it so that I could exhibit two or three of them standing up by themselves.
I imagine a long hallway that the audience could walk through while listening to those tireless conversations happening on the web - projections of the tweets text could happen on the side walls.
I personally believe that in this case interactivity wouldn’t be so essential and I could have just one head out of three holding a keyboard to let the audience type their own inquiries.
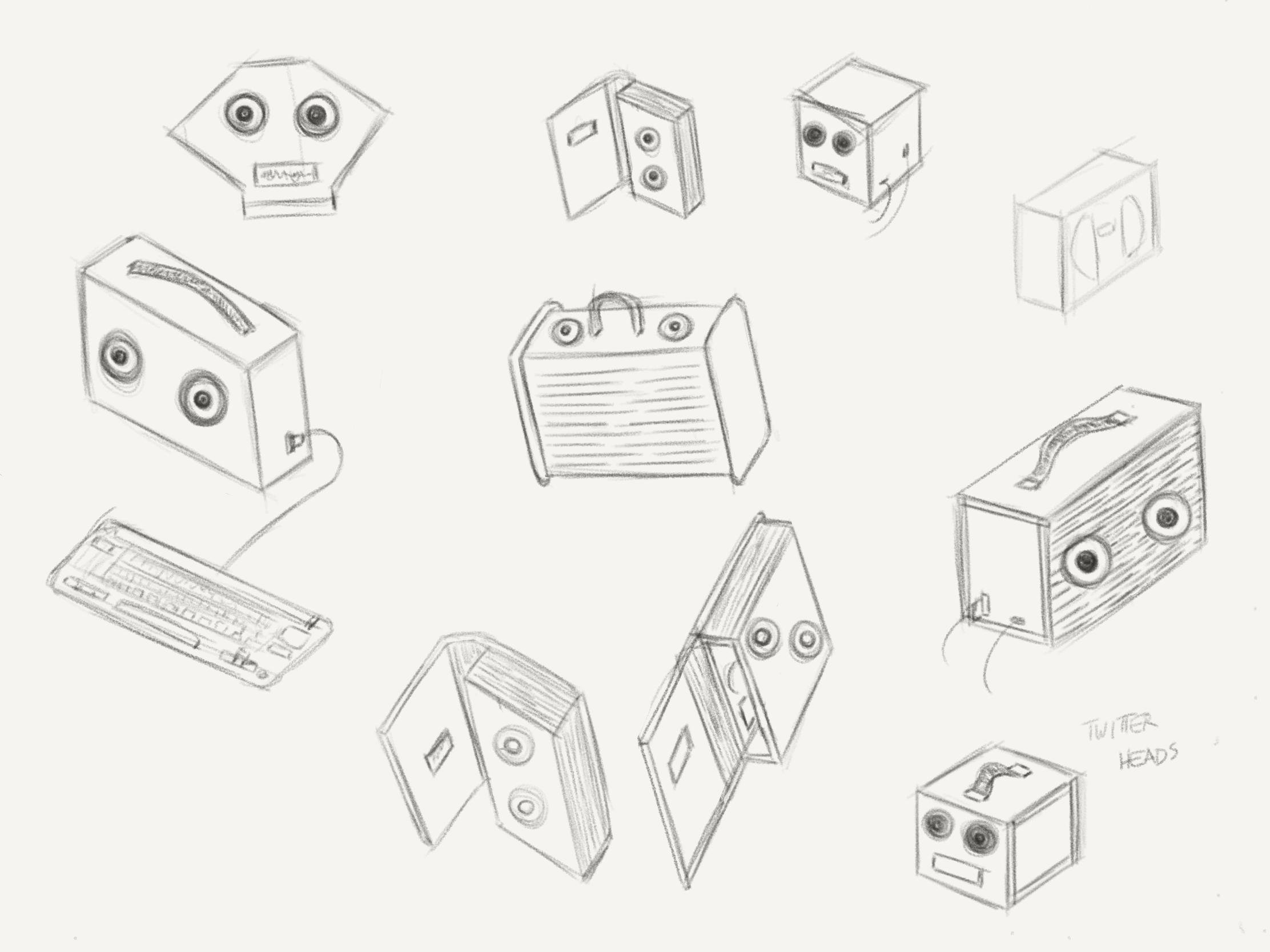
Initial sketches for the envelope:
Carboard prototypes:


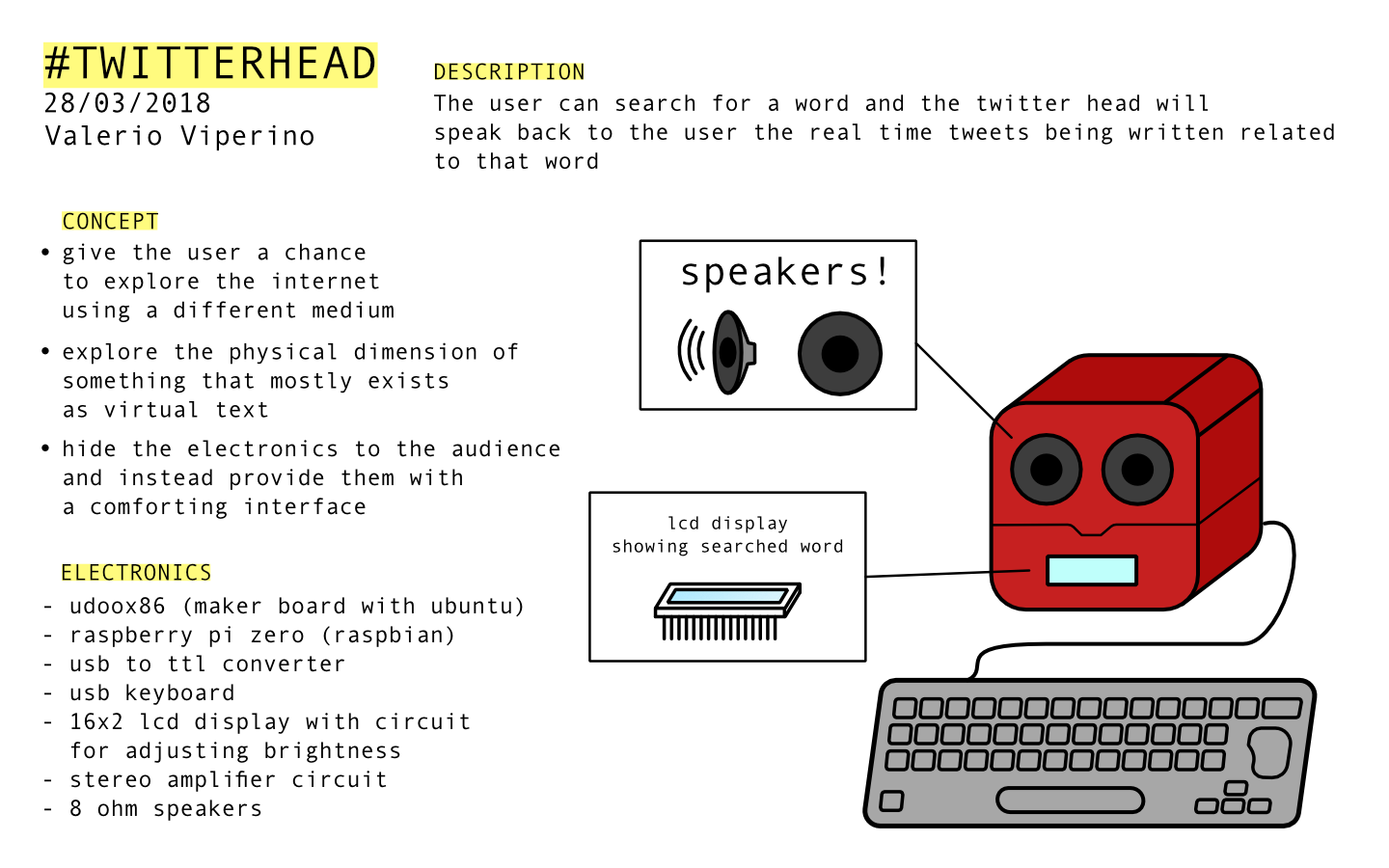
One page design:
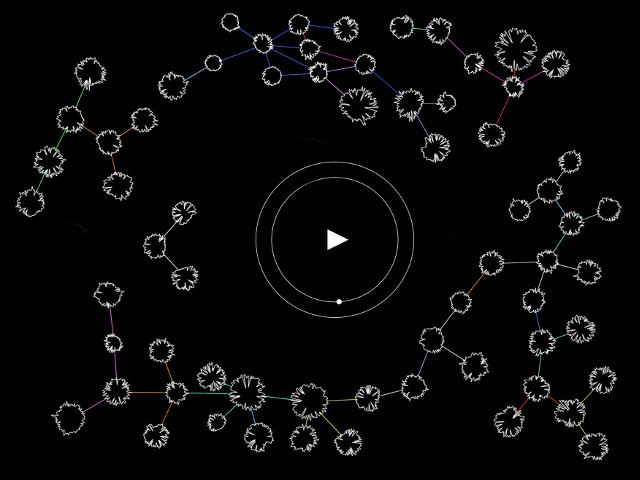
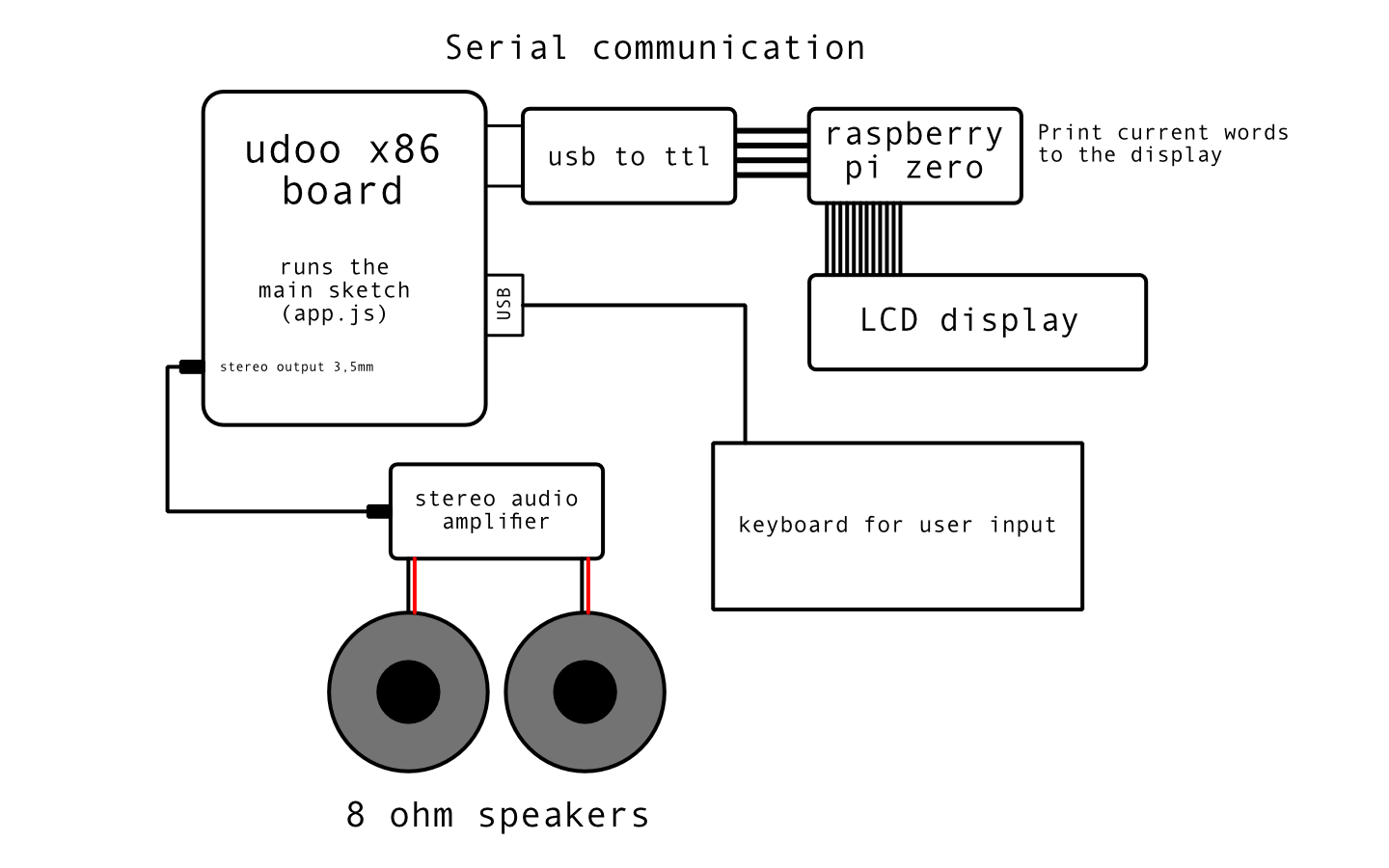
Scheme of the various connections:
Source code:
All of the source code (the nodejs app hosted on the udoo and the python app on the raspberry pi zero) are available on github: https://github.com/vvzen/twitter-radio
The node app makes use of the AWS sdk, the Speaker, Twit and SerialPort additional npm packages.
Inspiration:
Oh my () . An installation by Noriyuki Suzuki, as seen on Creative Applications : http://www.creativeapplications.net/arduino-2/oh-my-calling-for-god-in-48-languages-using-twitter-api/