




























































Within the Vibrant Assemblage
Within the Vibrant Assemblage is a performance of human and nonhuman participants who share a particular degree of dance aptitude and endurance. This work attempts to draw attention to a poetic and fuller range of the powers that circulate around and within actual and possible bodies.
produced by: Eirini Kalaitzidi
Introduction
Within the Vibrant Assemblage was created in response to a personal urge to exist bodily and sensorially awake within a space which is shared by human and nonhuman entities with a particular dance power. This dance power is the liveliness and the affective capacity that the theorist Jane Bennett attributes to vibrant matter. In this piece, the possible materiality and dimensionality of the vibrant matter found its expression in 2-dimensional projected visuals, 3-dimensional objects made out of wood, cotton and motors and the multi-dimensional human configuration of body joints.
Building on my theory research around the idea of ‘shaping a choreo-milieu to be in/with/within’, my intention when creating this piece was to suggest a choreographic practice that would diminish the authorship of the ‘head choreographer’ and would distribute the synthetic/choreographic activity to many human and nonhuman participants in the making process. In order to achieve that, I incorporated machine learning in my methods and welcomed 11 dancers and even more computational layers to be part of the choreographic milieu.
Concept n Background Research
Choreo-milieu, as a self-invented term, invokes ‘milieu’ to set the spatial nature for an ecology of bodily events and ‘choreo’ to set the dancing behaviour of bodies and things. Choreo-milieu is a dance-emerging space and practise descending from choreography but founded on agential realism. It is calling dance artists to be in/ with/ within it rather than to apply it like a mediating method between them and a potential output.
Machine learning is an insightful way to approach this theory since the incorporation of computational means in choreographic practises challenges the antagonistic dualism of the creator (choreographer) and the executor (dancer). When machines collaborate with humans, it is no longer obvious who is the mastermind and therefore where lies the authorship of a creative activity.


[fig 1] 'Living Archive' and 'Beyond Imitation' projects
My two main machine learning references are the project ‘Living Archive’ by Wayne McGregor and the project ‘Beyond Imitation’ by researchers from Yale and Harvard University. The latter created ‘a suite of publicly-accessible tools for generating novel sequences of choreography as well as tunable variations on input choreographic sequences using recurrent neural network and autoencoder architectures’, while McGregor along with Google Arts and Culture Lab created a tool that generates ‘original movement inspired by Wayne's 25-year archive, as a live dialogue between dancers and his body of work’.
In my case, machine learning will helps generate new sequences of movement based on 5,5 hours of improvised dance by 11 dancers. These sequences are then transfigured and embodied by a mobile configuration of motors, pixels, and body joints. A human-originated and computer-generated dance material is being displaced and redistributed among diverse bodies, creating a vibrant assemblage. These diverse bodies consist of visuals of humanoids, of motorised objects which have a subtle moving behaviour and of the human body improvising in space in a responsive but not descriptive way (action - reaction).
Technical
Recordings
The creative process started with the recordings of the 11 dancers improvising in space for 30 minutes each. In order to collect their data, I visited Athens where most of my college-dancers are based and arranged two days of recordings with them. I first needed to set-up the Kinect V2 and define the space within which the dancers could move, depending on its tracking distance range. Following that, the only instructions I gave to my collaborators were to not exceed the spatial borders, to pass through all levels (floor, medium and high level) and dynamics and to consider that whatever they provide bodily as data will constitute the 1/11 of the generated figure’ s dance training. By that, I encouraged them to be generous with their improvisation as if sharing part of their experience and bodily intelligence with a newborn dancer.











[fig 2] Participants: Fotis Haronis, Zoi Mastrotheodorou, Tasos Nikas, Xristina Prompona, Daphne Drakopoulou, Athina Stavropoulou, Angelos Papadopoulos, Areti Athanasopoulou, Myrto Georgiadi, Despoina Sanida Krezia, Irini Kalaitzidi. The recordings took place in Krama artspace and Artiria studio, Athens.
By the time the dancer and the sensor were ready, I ran the Processing sketch that was saving the tracked body joints’ coordinates (x, y, z) for each frame in a csv file. I chose to track 21 body joints which while being multiplied by the 3 coordinates resulted in 63 columns of data.

[fig 3] where ‘output’ is a PrintWriter object, hence the output csv file.
A technical requirement that troubled me as I am a Mac user, was that I needed Windows in order to install and run the Kinect for Windows Software Development Kit (SDK) 2.0. After attempting to install Windows on my iMac via bootcamp with no success (because it is an older version than 2015), I rented a Windows PC with directX 11.
Deep Learning Training in Google Colab
After collecting my data (11 files, one from each dancer) I started training a machine learning model in order to generate new sequences of movements. In the project I did for the course of Data and Machine Learning for Artistic Practise (term II) i used the same model with a much poorer training dataset which i collected with poseNet (https://github.com/tensorflow/tfjs-models/tree/master/posenet). PoseNet is an already trained machine learning model which allows for real-time human pose estimation in the browser (https://medium.com/tensorflow/real-time-human-pose-estimation-in-the-browser-with-tensorflow-js-7dd0bc881cd5). While I ended up being disappointed by the tracking accuracy of PoneNet, my goal this time was to improve my training dataset in terms of size and accuracy. This is something I had already accomplished in the previous step: Kinect offered me accurate 3-dimensional tracking and I had collected 5,5 hours of dance improvisational data (compared to the 30 minutes in total I used in my past project).
RNN models would allow me to operate over sequences of vectors; sequences in the input, the output or in most general case both. However standard RNNs are difficult to train for long-term dependencies in a stable way. For such cases, an LSTM model is the solution since it is stable over long training runs and can be stacked to form deeper networks without loss of stability.(Andrej Karpathy blog post: http://karpathy.github.io/2015/05/21/rnn-effectiveness/)
“LSTMs are a special kind of RNN, capable of learning long-term dependencies. They were introduced by Hochreiter & Schmidhuber (1997) and were refined and popularised by many people in following works. They work tremendously well on a large variety of problems and are now widely used.” (Colah’s blog post: http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
Therefore, with this supporting theory, LSTM was the model to use in order to provide sequences of movements as input and generate sequences of movements as output. In my case, the sequences of movements are in the form of sequences of rows of values (x, y, z coordinates of body joints, in the way my dataset is structured).
My laptop remained an issue because i do not have a GPU to support the training process. This is the reason i only trained my model in Google Colab (in Python 3). Google Colab is a free Jupiter notebook environment where I could write and execute my code entirely in the cloud, with access to powerful computing resources. (https://colab.research.google.com/notebooks/welcome.ipynb)
I browsed around GitHub in search for libraries and references relative to my ideal LSTM model. After trying out various resources and combinations of those, I ended up with these three as my guide:
- https://machinelearningmastery.com/time-series-prediction-lstm-recurrent-neural-networks-python-keras/
- https://machinelearningmastery.com/5-step-life-cycle-long-short-term-memory-models-keras/
- https://github.com/keshavoct98/DANCING-AI
The process of training in Google Colab was painful. My laptop crashed countless times and hours of waiting for the training to be completed (overnight trainings) went to waste. After all, I got results that were not as rich as I would imagine and hope for. The generated sequences of movements were mostly resembling to squats in repeat. The 5,5 hours dataset that I have composed out of the total of dancers seemed to be too much and too diverse information for the model to learn. This is the reason I continued the trainings with modified training datasets until I curate the results the way I envisioned.
Visuals in Processing
Despite my efforts, the generated movements never reached the richness and complexity i was hoping for. This is the reason I mixed the generated data with the original tracked data in the files I used for my visuals. Having my csv files ready to be read and interpreted visually, I wanted visuals to reflect the raw materiality of the computational movement sequences which actually was the materiality of the numerical data (body joints' coordinates). Either these datasets were generated, original or hybrid, they were undoubtedly computer-mediated and therefore figured as numbers in the range (-1, 1) as everything was calculated in P3D.

[fig 4] Numerical values, figures and a rough representation of the boxes as possible bodies of the datasets. This is a random vertically compressed diplay of the objects. I did not use this structure in the final version although I really like it.
I incorporated a matrix aesthetics and decided to gradually present the transition from numbers to single body joints and then to the whole skeleton figures, the humanoids. I enjoyed the messiness and the plurality of these projected numbers, joints and figures. I feel confident that it reflected nicely and effectively the flow of the dynamic data and equally the dance power circulating among and within the bodies. Practically, all the chosen expressions of the dataset were organised in ArrayLists of Objects (Dancer.pde, Box.pde, Joint.pde, Value.pde).
At the background of the visuals I added a close-up video of the cotton material that was used in the motorised objects (the other participant of this choreo-milieu) for the purpose of visual cohesion.
For the actual performance, the visuals were running real-time in G05' s MacPro, in Processing and sent to MadMapper (which was already setup for G05' s projection needs) through Syphon. At the same time, the Processing sketch was communicating through OSC messages with my Max/MSP patch (which i will describe in detail below) running in my own laptop on stage. The messages were bangs that triggered gradual changes in the sound environment depending on the projected visuals. This resulted in a synchronised visual and acoustic event.
Motorised Objects
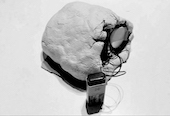
The motorised objects were the thing that troubled me conceptually the most. Until then and throughout my practise as a dance artist, I was always concerned about the moving behaviour of things and bodies. I was never worried about the material form, shape, immobile schematic expression of them and at this point I was called to design a possible body. I gathered all the clues that interested me and started a long lasting brainstorming. It would not be one thing but 7 in total; as many as the basic number for a skeleton' s body joints. Since their movement would derive from body joints’ data (z coordinate of head, left arm, right arm, left pelvis, right pelvis, left foot, right foot) they should all have the same materiality but not quite the exact same form. Therefore I was looking for an irregular material and after various experimentations, i came up with cotton. Moreover, while wanting to combine earthly, stable and inanimate qualities along with unearthly and dynamic qualities, I came up with a static base underneath the cotton; something to contain and support it. Gradually this mind pathway led me to the creation of the final boxes/ clouds/ sheep/ things, depending on how they are perceived. The base/ container is constructed by me, with MDF wood (6 milimeters thick).
As physical computed objects, the boxes’ mechanisms consist of:
- an arduino nano board (Elegoo clone)
- an sd card loaded with the generated z values of one of the joints mentioned above
- an sd card reader
- a servo motor
- a 9V battery for the arduino
- a 6V battery (4*1,5V AA batteries) for the motor (connected grounds between the two power sources)
- a switch to turn the system on/off
The generated z values were mapped into rotation values for the motor to follow accordingly. This translation is part of the wanted displacement and redistribution of the human-originated and computer-generated dance material among diverse bodies.
[fig 5] The making process of the boxes.
Sound environment
Since the element that prevails throughout the creative process is the harmonical and mutually affective existence of human and nonhuman elements, i decided to embrace that in my sound design as well. This time I did not want to use the generated data. I solely wanted to surround the fictional choreo-milieu I/we created with a sound environment that would accompany the kinetic event. Accordingly, I amplified the sound of the servo motors by using piezo sensors (https://www.youtube.com/watch?v=_pkQF5zR8Oo) that sense the tiniest emerging vibrations (nonhuman element) and I synthesized a more melodic and subtler music in Max/MSP (human element). The amplifying system was composed by:
a 9V battery
a piezo sensor and
an LM386 audio amplifier module for Arduino
which was connected to an external sound card through a jack cable and from there, to my laptop and my Max patch in order to process the input sound (mostly added reverb to it). The second part of the sound environment was a combination of FM (frequency modulation) synthesis and editing small tweaked (frequency and speed -wise) extracts from Mammal Hand’ s jazz song ‘Hilum’.
[fig 6] The amplfying system. Checking its sensitity to the smallest movements.
[fig 7] One of the first synchronous activations of the boxes and the projections.
Self-Evaluation n Future development
Overall I am very satisfied with the outcome of my summer research and development. I believe I created an art piece that constitutes both a research project at the intersection of choreography and technology and a purely choreographic piece to present on stage.
The main questions regarding my methods pertain to the extent to which i truly managed to diminish the authorship of the ‘head choreographer’ and his/ her/ my control over things. Considering that distributing the decision-making power to more human and nonhuman participants was the conceptual and ideological guideline of my process, I partly feel that I disregarded it whenever it was not convenient for me. I am aware that I curated everything and particularly the generated sequences of movements. Although they are computer-mediated, the are also adulterated with my tweaks after filtering whatever I see through my artistic scope and expectations.
Relating to that, my main goal is to keep improving my deep learning model until it reaches a stage where i will no longer need to adulterate its output; until it learns to generate what matches my aesthetics. For this project i did not change or expand on the LSTM model which I had already used in my previous project (term II). Instead, I emphasized on improving the training dataset which is fundamentally important. But since this is now accomplished, the next step is to expand on the actual model and probably combine it with Mixture Density Networks (https://publications.aston.ac.uk/id/eprint/373/1/NCRG_94_004.pdf) which will enrich the predictions of new movements.
After all, for my deep learning plans, a gaming laptop with a strong GPU is one of the following investments i need to make.





[fig 8] Various photos from the performance.
References
- Barad, K. (2007). Meeting the Universe Halfway: Quantum Physics and the Entanglement of Matter and Meaning. Duke University Press Books.
- Bennett, Jane. (2009). Vibrant Matter: A Political Ecology of Things. Duke University Press Books.
- Pettee Mariel, Shimin Chase, Duhaime Douglas and Ilya Vidrin. Beyond Imitation: Generative and Variational Choreography via Machine Learning. Proceedings of the 10th International Conference on Computational Creativity 2019 ISBN:978-989-54160-1-1. http://beyondimitation.com
- Luka Crnkovic-Friis and Louise Crnkovic-Friis. Generative choreography using deep learning. 7th International Conference on Computational Creativity, ICCC 2016.
- https://github.com/keshavoct98/DANCING-AI (source code for the training model)
- https://machinelearningmastery.com/5-step-life-cycle-long-short-term-memory-models-keras/ (source code for the training model)
- https://waynemcgregor.com/research/living-archive/ Living Archive project by Wayne Mc Gregor
- Understanding LSTM networks http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- The Unreasonable Effectiveness of Recurrent Neural Networks http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- https://medium.com/@kcimc/discrete-figures-7d9e9c275c47
Special thanks to Keita Ikeda, Harry Morley, Julien Mercier, Benjamin Sammon, David Williams, Valeria Radchenko, Ankita Anand, Raphael Theolade, Rachel Max and Chris Speed for their support and their cooperation whenever needed.