




























































Introduction
Cady Herring, Nathan Adams, Uchan Soon and Seyeon Park
Our Artifact - Al1c3
This work was inspired during the research about material semiotics, which regards both humans and objects as the joints in the network of affective connections. This gave us another way looking at the meaning of “narratives”: creating new stories is to walk through the network of the original text.
Using Rita.js, we picked out every nouns, adjectives, and verb to create a scattered map of terms in Alice in the wonderland. The new combination of keywords will be set while the user moving the mouse through the map. Then it comes to the question of text generation.
Usually, in most hypertext works, including interactive fiction and digital literature, new text can be produced through a Markov chain, based on the input paragraph rather than keywords. This algorithm is more like the available process of creating new sentences rather than “stories”. Besides, the generative text from the Markov chain won’t jump out the scale of the original text. This drew to another question: is it possible for a player/reader to continue the story in his or her way while reading?
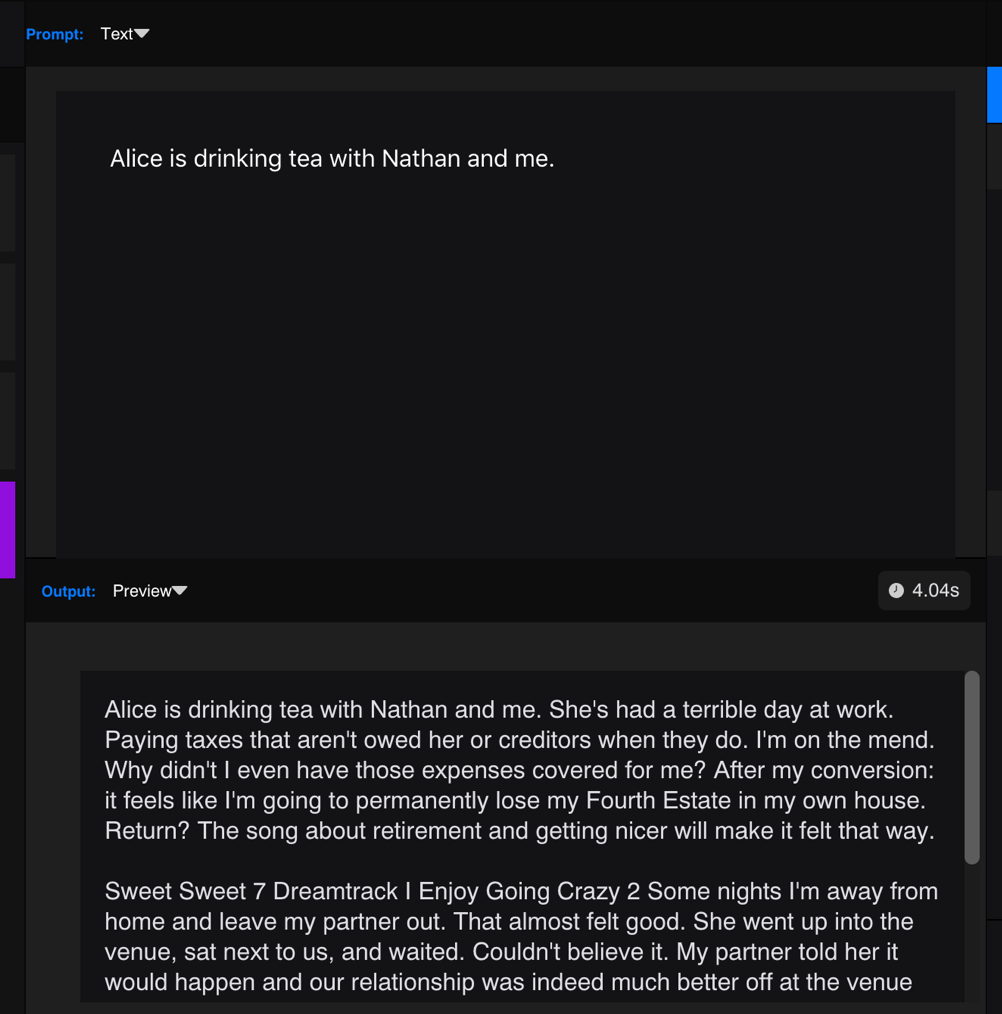
GPT-2 made it possible. GPT-2 can generate paragraphs of text from a prompt, so it leads to a new method of expanding the story, jumping out of the limitation of the original text.
From Prototype to Artifact
As we progressed through our research, what become clear was that we needed to analyse the structure of an existing text, rather than just create a random map.
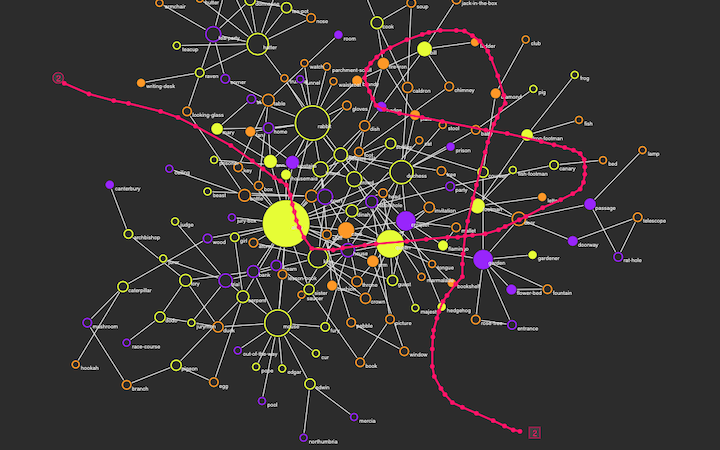
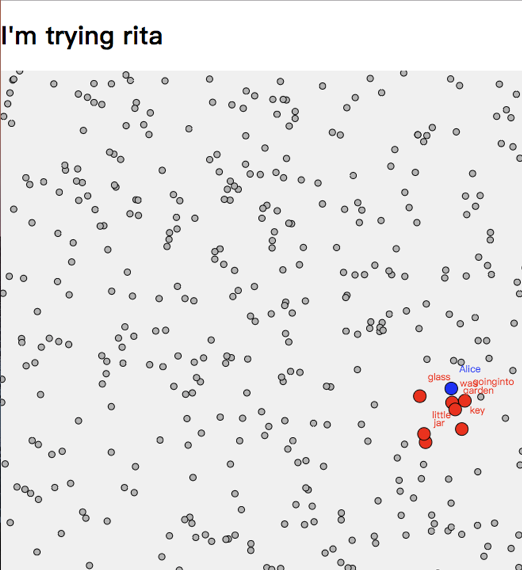
Building on the work done using RiTA, we ideintified the key nouns, adjectives and verbs we were intested in. Mostly the word of interest identified were nouns. These were then classified into Characters, Locations and Objects (not always so easy in a rich text like Alice in Wonderland, where there is at time deliberate confusion and overlap in these). From this we manually analysed relationships between these key objects. This manual analysis was achieved by looking at nearby relationships of words, to help establish meaningful links. It would in future, be interesting to see what algorithms could be employed to automate this task - adding, an additional computational aspect to the process.
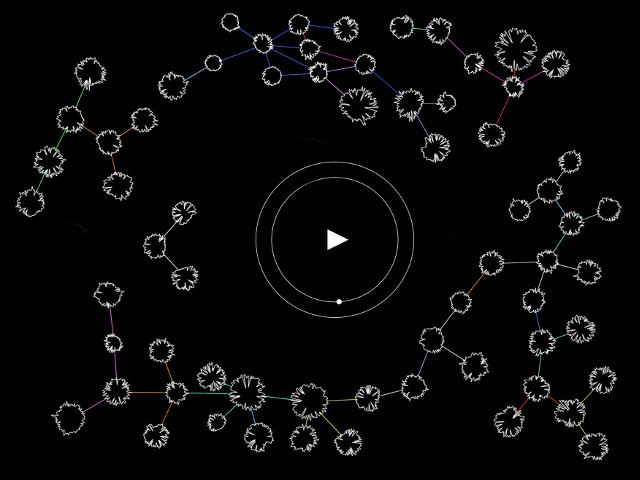
Using these relationships, we then created a force directed graph[1] - in effect a self organising diagram of the structured text. In the force directed graph, each node in the graph has an attractive force (typically set to repel other nodes, else the diagram collapses in on itself), and for each relationship springs are attached between related nodes, which counter this negative attraction.
We adjusted the force directed graph, by taking account of the following factors
- The size of a node, and it's negative attractive force was based on the number of connections the node had to other objects
- The length of the spring is determined by a score created in the analysis phase - see below for more details
- The strength of the spring, is also based ont he number of connections the node has to other nodes.
These were adjusted till a satisfying balance between nodes, and relationships was found - one that would allow the user / reader to create a path through the graph, to create their own remixed text
The score for each relationship was calculated as follows
var score = _from.indicies.reduce((_score, _index) => {
_score = _score + _to.indicies.filter(f => abs(f - _index) < 200).length;
return _score;
}, 1); //start from 1 as minimum score
That is, it is made up of the count of how many other references are within 200 words to the original word reference. This approximates creating stronger links between references which clump together - as opposed to ones more distributed through the novel.
The analysed results can be found in the gitlab repository for the artifact, here https://gitlab.com/al1c3/al1c3_2019
The artefact can be run here https://al1c3.gitlab.io/al1c3_2019/
[1] - http://www.generative-gestaltung.de/2/sketches/?02_M/M_6_1_03