




























































Poiesis, there is no need to see
An interactive installation and performance imagining a metaphysical world where ideas precede and realities exist in our own imagination, and contradict it with action.
produced by: Betty Li
Introduction
Poiesis, there is no need to see uses computer vision, machine learning, and performance to tell a story in the perfect otherworld where thinking is becoming. When our thoughts are omnipotent, what becomes the reality? If we exist to produce and consume ideas, then who owns those ideas? By reading a conceptual poem I've written and dancing improvisationally to the program, the performance was completed in a machine-human collaboration where the machine picked up my speech and body movements and generate visual outputs in return.
Concept and background research
The piece is inspired by conceptual art, where the idea is the most important aspect of the work and "becomes a machine that makes the art" (Sol LeWitt). The artwork I reimagined is Wall Drawing 273 by Sol LeWitt. It is an instruction-based artwork where Sol LeWitt hired individuals to construct installations based only on his instructions. His instructions left much open to interpretation and no two installations ended up being identical. Even though the constructors introduced randomness to the work, these drawings are still entirely owned by Sol LeWitt. It opened up a conversation about the authorship of ideas, power, and control for me, especially relating to generative art where machines follow our code as instructions but still bring surprisingly rich uncertainties to the final outcome.
On the contrary to Sol LeWitt and most conceptual artists' opinion, I argue that the authorship of an idea is a shared property between the idea generator and its interpreter/executor. An idea is never entirely owned by the idea generator even if it is never said/interpreted(considering no idea is original). Taking this statement into the context of digital art, the machine is not merely the follower of our programming instructions, but a collaborator to build the artwork with the coders. Artwork is fully realized only when both the idea and production are taken into consideration.
Based on this research and investigation, I wrote a conceptual poem( relating to conceptual art, where you sample other poets/writers' words or alter them to express your own idea) and trained a speech recognition model that allows the machine to pick up certain words when I read my poem and run commands according to the word. Meanwhile, the Kinect will track my dancing movement and respond with visual effects.

Wall Drawing 273, Sol LeWitt, 1975 (Instruction & Installation)
Technical
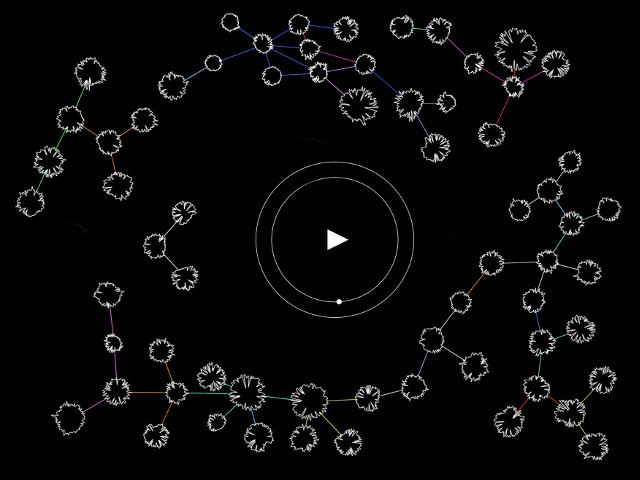
The first problem I tried to solve is how to train the machine learning model and where to host it so the information can be collected by Openframeworks. I tried addon ofASR and audioclassfier from ml4-ofx for voice detection but the precision was not quite ideal. So I ended up training my model on Teachable Machine where you can upload your model to their cloud or download it for free for use in Java. I wrote a P5js program to analyze the voice input based on the trained model and send OSC messages to Openframeworks once the keywords are detected from my speech. A P5js-OSC bridge script was also used for P5js to send OSC messages to OF. For the computer vision part, I was using Kinect to capture the depth images of my movements, and utilizing the data with Opticalflow and OfxCv contour finder. Then visuals will be generated correspondingly. For the visual, I was using ofxFluid to create fluid stimulation in reaction to my performance. I also used particlesystem to better accommodate the content of my poem.
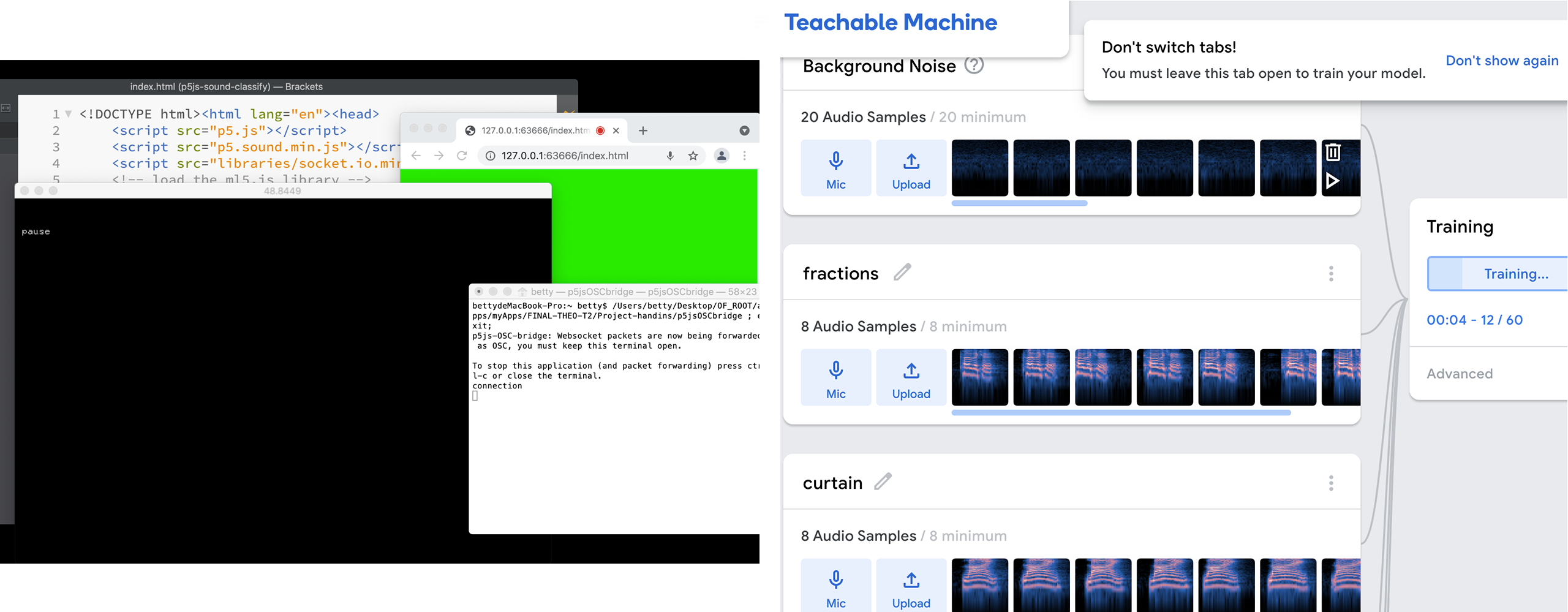
P5js ommunicating speech detection result with OF through OSC / training speech recognition model on Teachable Machine
Self-evaluation
Overall I am satisfied with my conception and performative approach to link up early conceptual art ideas with new technologies in this piece. I am also happy with how the visuals reacting to the input data, and the story was unfolded in the tone I intended: airy and tranquilizing. One thing I think I could improve is the connection between the keyword I've chosen for speech recognition and the visuals. It could be more cohesive when the "word instructions" are tightly related to the visuals shown. Another thing I need to plan better is the hardware capacity. When I was running the microphone, Kinect, P5js, the bridge script, OSC communication, and my visual system all at the same time, my laptop became extremely slow, and there was a noticeable lag for the OSC messages to send through. So if it were performing live, I need a better solution for seamless communication and run.
Future development
I envision this piece to be an interactive installation in galleries where the audience can speak to the microphone and the keywords in their speech transformed into visuals on the display screen. The biggest obstacle to this idea is how to train/host a very large speech recognition model in the program. And then how to run the program seamlessly, considering the model might not be able to detect the keywords every single time. It could also potentially be an ongoing personal project where I read my own writings to the machine, and it generate graphics based on my writings accordingly. Again, it needs a very large speech recognition model to include a substantial number of words.
References
Addons: ofxFluid, ofxOpenCv, ofxKinect, ofxOsc
Teachable Machine for training the model: https://teachablemachine.withgoogle.com/
P5js voice recognition example and OSC-P5js-Bridge from Data and Machine Learning for Artistic Practice by Joe McAlister
OSC Receiver example from Workshops In Creative Coding II Week 15
Optical Flow example from Workshops In Creative Coding II Week 12
Contour finder from the example in ofxcv addon
Particlesystem from Computational Form and Process by Andy Lomas